
Random sampling is a probability-based way of selecting people, cases, records, classrooms, households, sites, or observations from a larger population. Instead of choosing the units that are easiest to reach or most familiar to the researcher, the selection is guided by chance. This gives each eligible unit a known chance of entering the study and helps the sample stay connected to the population the study wants to describe.
This article explains what random sampling is, how it fits into research design, which main types are used, when it is suitable, how to carry it out, and what advantages and limitations researchers should keep in view when interpreting results.
What Is Random Sampling?
Random sampling is a probability sampling method in which chance is built into the selection process. A researcher first defines the population, identifies a practical way to reach that population, and then uses a random procedure to decide which units enter the sample. The word random does not mean casual, unplanned, or haphazard. It means that the selection follows a chance-based rule rather than personal preference.
Imagine a university researcher who wants to study study habits among all first-year students at one university. Asking only students in one lecture hall would be convenient, but that group may not reflect the full first-year population. A random sample would begin with a list of eligible students, then use a random number generator or similar tool to select the students who will be invited. The researcher still has to handle consent, non-response, and missing data, but the starting point is no longer the researcher’s convenience.
Random sampling definition
Random sampling means selecting units from a defined population through a probability-based procedure, so that each unit has a known chance of selection. In simple random sampling, each unit has an equal chance. In other forms, such as stratified or cluster sampling, the chances may differ across stages or groups, but the probabilities are still known or planned.
This difference between known chance and equal chance is useful. Many beginners first learn random sampling as the method where everyone has the same chance of being chosen. That is true for simple random sampling. It is not the whole family. A stratified design may deliberately sample more heavily from a small subgroup so that the subgroup can be analysed. A cluster design may randomly select schools first and students later. Both can still be random sampling designs because the selection process is governed by probability.
Population, sample, and sampling frame
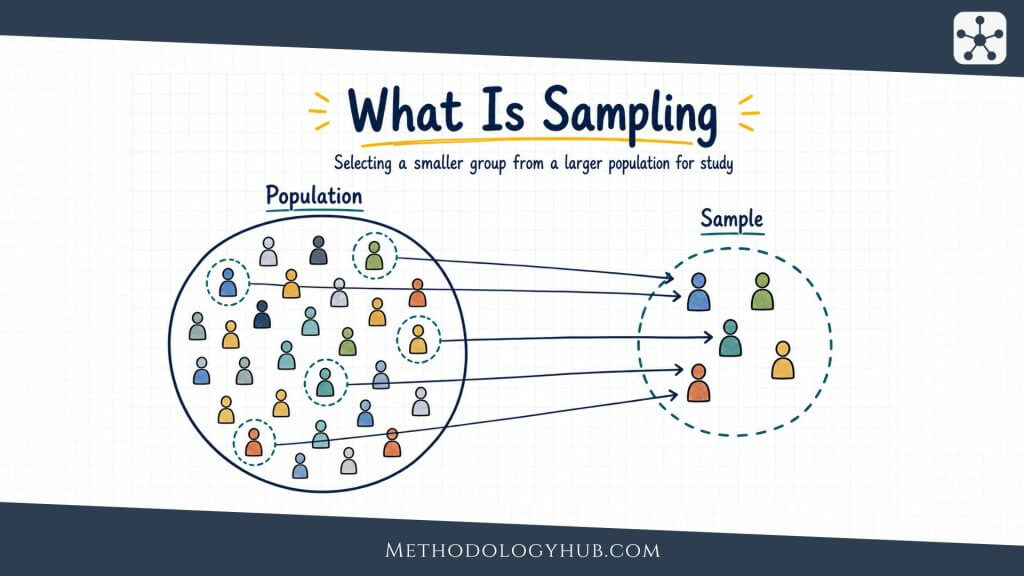
Random sampling begins with the population. The population is the full group the research question is about. It may be all pupils in a district, all patients treated in a clinic during a defined period, all articles published in certain journals, all households in a region, or all soil samples taken from a field. The sample is the smaller set that is actually observed.
Between those two sits the sampling frame. This is the list, register, database, map, roster, or other practical route from which the sample can be selected. A random sample is only as good as the connection between the frame and the population. If the frame misses part of the population, the random procedure cannot select those missing units.
Random sampling and probability sampling
Random sampling belongs to the wider family of probability sampling. In probability sampling, selection is based on chance and the chance of selection can be described. This is the feature that allows researchers to estimate sampling error, build confidence intervals, and use many tools from inferential statistics.
Non-probability sampling works differently. A purposive interview sample, a convenience sample, or a snowball sample can be useful in many studies, especially when depth, access, or specialised experience is central. Those samples, however, do not give every member of the population a known selection probability. For population estimates, random sampling usually gives a stronger basis when it can be implemented properly.

Random selection is not the same as random assignment
Random sampling and random assignment are often confused because both use chance. They answer different design questions. Random sampling concerns who enters the study from the population. Random assignment concerns how participants already in the study are placed into groups, such as treatment and comparison groups.
A study can use one without the other. A survey may use random sampling but no random assignment, because it simply observes the selected people. An experiment may use volunteers and randomly assign them to two teaching methods, but the volunteers were not randomly sampled from all students. The difference affects interpretation. Random sampling supports statements about a population. Random assignment supports stronger comparison between conditions inside the study.
Why Use Random Sampling?
Researchers use random sampling when they want a sample that can support careful statements about a wider population. The method reduces the role of personal choice in selection. It does not remove every possible source of error, but it gives the study a clearer statistical foundation than a sample chosen only because it is available.
The main value is the link between sample and population. When a random sample is drawn from a suitable frame and the response process is handled well, the researcher can estimate how much sample results would vary from sample to sample. That is why random sampling appears so often in surveys, health studies, education research, population studies, environmental monitoring, and other projects where estimates are made from a smaller set of observations.
Reducing selection bias
Selection bias appears when some units are more likely to enter the sample in a way that affects the result. A teacher who surveys only the most engaged students may get a distorted view of learning habits. A health researcher who collects data only from people who attend morning appointments may miss people with different work schedules. Random sampling cannot solve every access problem, but it reduces the researcher’s direct control over who appears in the sample.
This is especially helpful when the researcher does not know in advance which characteristics will be linked to the outcome. A random procedure can spread selection across the sampling frame without relying on the researcher’s judgement about who looks typical.
Supporting statistical inference
Random sampling also supports statistical analysis that moves beyond the observed sample. A sample mean, proportion, correlation, or regression coefficient may be used to estimate a population value. Confidence intervals, standard errors, and many forms of hypothesis testing depend on assumptions about how the sample was drawn.
For example, if a district randomly samples pupils to estimate average reading time, the final estimate is not treated as a perfect population value. It is treated as a sample-based estimate with uncertainty. Random sampling gives the researcher a way to describe that uncertainty rather than leaving it vague.
Making the sampling process transparent
A random sampling plan is usually easier to describe than an informal recruitment process. The researcher can report the population, sampling frame, sample size, randomisation method, response rate, exclusions, and final analytic sample. Readers can then judge the design more clearly.
This transparency is useful for students learning research methods as well as for experienced researchers. A statement such as “300 students were selected using a computer-generated random sample from the enrolment list” gives the reader more information than “students were asked to participate.” It shows the route from population to sample.
Key Types of Random Sampling
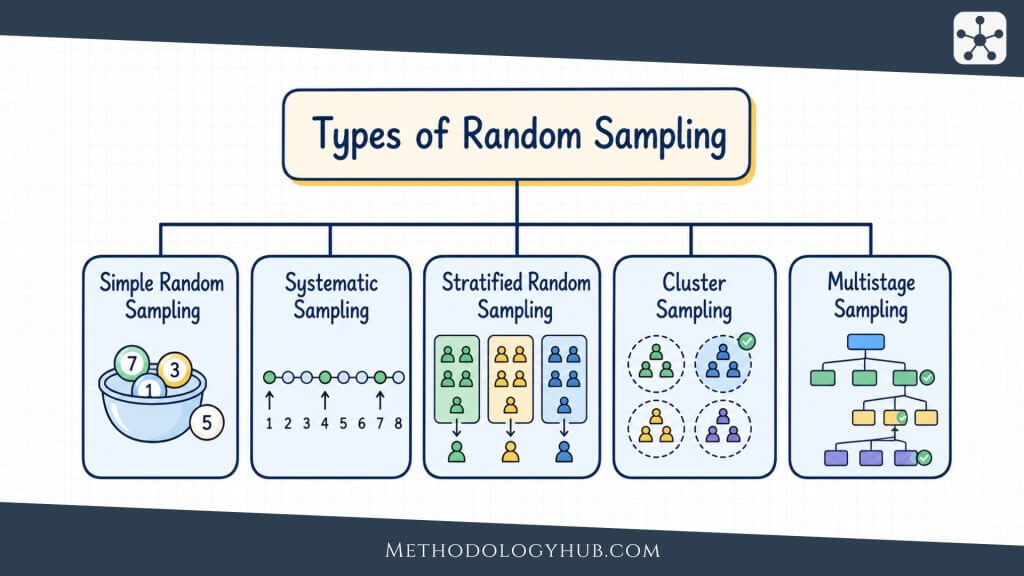
Random sampling is not one single procedure. It is a group of related methods that use chance at one or more stages of selection. The best-known types are simple random sampling, systematic sampling, stratified random sampling, cluster sampling, and multistage sampling. Each one handles the same basic problem in a different way: how to move from a population to a sample without relying only on convenience or judgement.
The choice depends on the research question, the population structure, the available sampling frame, the need for subgroup analysis, and the practical conditions of fieldwork. A national school survey, a small classroom study, a hospital records study, and an environmental sampling project may all use chance, but they rarely use it in exactly the same form.
Simple Random Sampling
Simple random sampling is the most direct form of random sampling. Every unit in the sampling frame has an equal chance of being selected. If the researcher needs 200 cases from a list of 2,000, each case on the list should have the same probability of entering the sample.
The method is easy to explain. The researcher defines the population, prepares a complete list, assigns each unit a number, and uses a random number generator, random number table, or software procedure to select the required number of units. The selection should not be adjusted because one name looks more useful or because another seems difficult to contact. Once the sample is drawn, the researcher follows the planned contact and data collection procedure.
Simple random sampling works well when the population is clearly listed and reasonably homogeneous for the purpose of the study. It is often used in teaching examples because the logic is clear. In real research, the challenge is usually the frame. Complete lists are not always available, and even when they exist, some groups may be too small to appear in useful numbers by chance.
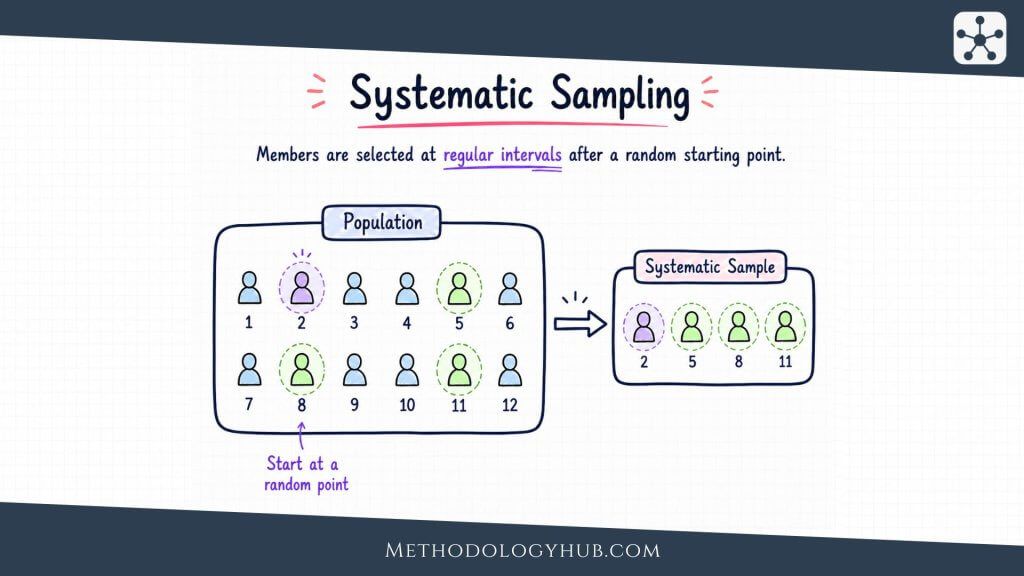
Systematic Sampling
Systematic sampling selects units at fixed intervals after a random start. Suppose a researcher has a list of 4,000 eligible records and wants a sample of 400. The sampling interval is 10. The researcher chooses a random start between 1 and 10, then selects every 10th record from that point onward.
The method is often simpler to carry out than simple random sampling, especially when working with long lists, ordered registers, physical files, or field routes. It spreads the sample across the frame and can be efficient when the list is already available.
The main caution is hidden patterning in the list. If the order of the list repeats in a way that lines up with the interval, systematic sampling can tilt the sample. For instance, if a clinic list is arranged by appointment type and every 10th record belongs to the same type of appointment, selecting every 10th record would not behave like a neutral spread across the population. The researcher should inspect the ordering before using the method.
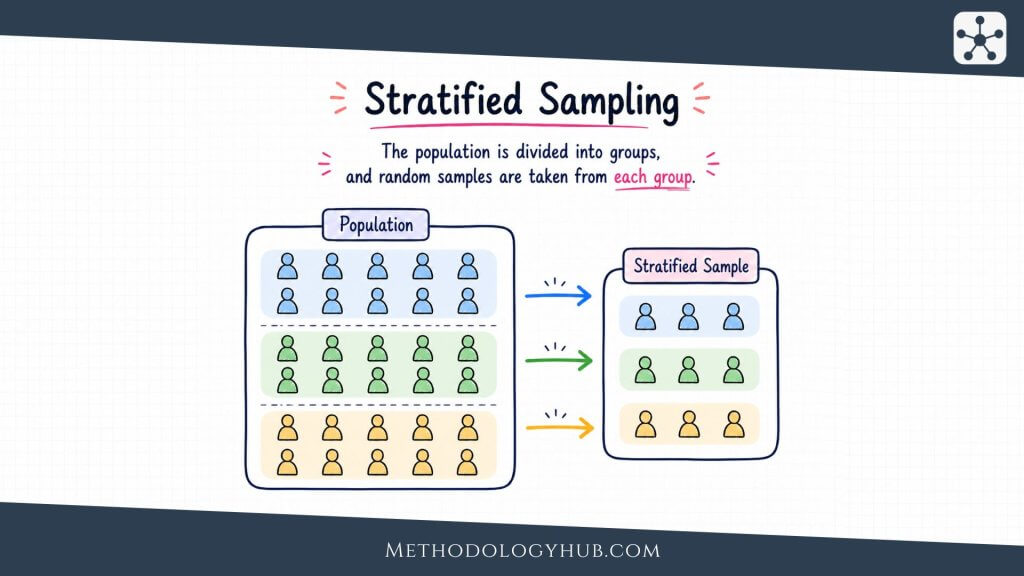
Stratified Random Sampling
Stratified random sampling divides the population into subgroups, called strata, and then randomly samples within each stratum. The strata are chosen before sampling begins. They usually reflect characteristics that are relevant to the research question, such as school level, region, age group, course year, clinic type, or diagnosis category.
This method is useful when the researcher wants subgroup representation built into the design. In a simple random sample, a small subgroup may appear in very small numbers just by chance. Stratified random sampling prevents that problem by selecting from each subgroup separately.
There are two common forms. In proportionate stratified sampling, each stratum appears in the sample in the same proportion as in the population. If 30% of the population belongs to one stratum, about 30% of the sample comes from that stratum. In disproportionate stratified sampling, the researcher intentionally samples some strata more heavily, often because small groups need enough cases for comparison. When this happens, the analysis may need weights so that population estimates are not distorted.
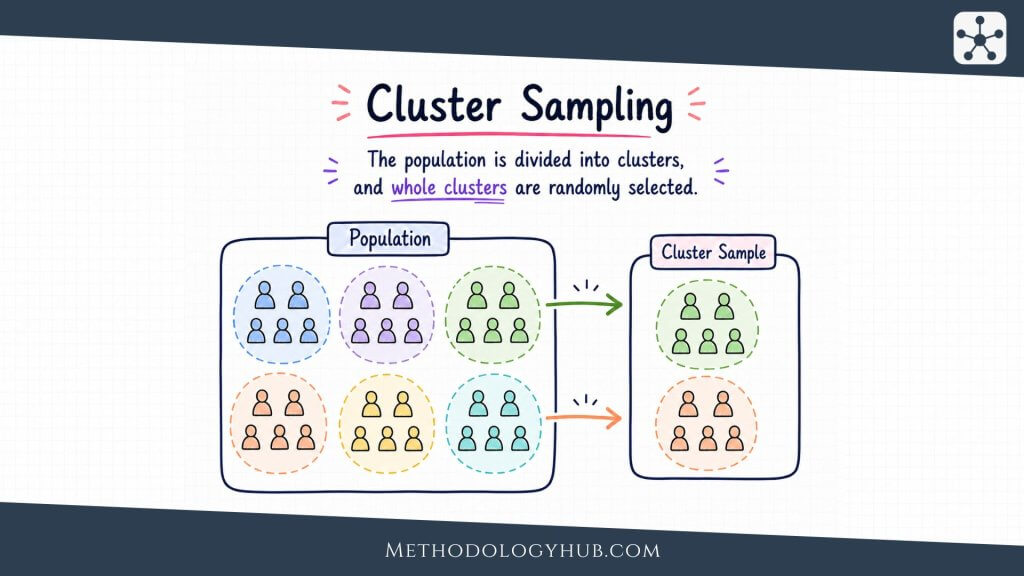
Cluster Sampling
Cluster sampling randomly selects groups rather than selecting all individuals directly from one complete list. The groups are called clusters. They may be schools, classrooms, neighbourhoods, hospitals, villages, households, laboratories, or other naturally occurring units.
The method is useful when the population is geographically spread out or when a complete list of individuals is difficult to build. A researcher studying pupils across a large region may not have a single list of all pupils, but may have a list of schools. The researcher can randomly select schools first, then collect data from all eligible pupils in selected schools or sample pupils within those schools.
The practical advantage is clear. Cluster sampling can reduce travel, administration, and listing work. The statistical trade-off is also clear. Units inside the same cluster often resemble one another. Pupils in the same school may share teachers, policies, resources, and local conditions. Patients in the same clinic may share service routines. Because of this similarity, cluster samples often need larger sample sizes than simple random samples to reach the same precision.
Multistage Sampling
Multistage sampling uses random selection at more than one stage. It is common in large surveys where selecting individuals directly from the whole population would be too difficult. A study may randomly select regions, then schools within regions, then classrooms within schools, then pupils within classrooms. Each stage narrows the field while keeping chance in the selection process.
This design is flexible. It allows researchers to work with complex populations and practical field conditions. It also requires careful documentation. The researcher should explain each stage, the sampling frame used at that stage, the probability rule, and the number of units selected. In quantitative studies, the analysis may need to account for clustering, stratification, and unequal probabilities of selection.
Multistage sampling is sometimes confused with cluster sampling because both may begin by selecting groups. The difference is that multistage designs continue sampling within selected groups. A one-stage cluster sample might select classrooms and include every pupil in those classrooms. A multistage sample might select classrooms and then randomly select pupils inside them.
| Type | How selection works | Good fit |
|---|---|---|
| Simple random sampling | Selects units directly from a complete frame with equal chance. | Clear, listed, fairly compact populations. |
| Systematic sampling | Selects every kth unit after a random start. | Long lists without hidden repeating patterns. |
| Stratified random sampling | Divides the population into strata and samples within each one. | Studies needing subgroup representation. |
| Cluster sampling | Selects natural groups, then studies all or some units inside them. | Spread-out populations with natural groupings. |
| Multistage sampling | Uses random selection across several levels. | Large, layered, or geographically dispersed studies. |
When to Use Random Sampling?
Random sampling is most suitable when the study asks a question about a defined population and the researcher wants the sample to support population-level interpretation. This usually means the research question involves estimating an average, proportion, distribution, association, or difference for a larger group.
The method fits especially well when the population can be described clearly and a reasonable sampling frame exists. Without that frame, the random procedure may look good on paper but fail in practice. A random number generator cannot select people who are missing from the list, households absent from the address database, or records that were never entered into the register.
Use it for population estimates
Random sampling is a strong choice when a study wants to estimate a population value. A school district may estimate the average number of minutes pupils read outside class. A public health study may estimate the proportion of patients who received a follow-up appointment. An environmental study may estimate the average level of a measured substance across a defined area.
In each case, the sample result is not the final population truth. It is an estimate. Random sampling lets the researcher connect that estimate to sampling uncertainty, which can be reported through standard errors, confidence intervals, or other inferential tools.
Use it when subgroup coverage can be planned
If the research question includes comparisons between subgroups, random sampling may still be suitable, but the type must be chosen carefully. Simple random sampling may not include enough people from small subgroups. Stratified random sampling is often better when groups need to appear in planned numbers.
For example, a researcher studying academic support among undergraduate students may need enough first-year, second-year, and final-year students to compare their experiences. A simple random sample might produce uneven counts. A stratified design can sample within each year group and make the comparison more stable.
Use it when the analysis depends on sampling assumptions
Many statistical procedures assume that observations are independent and that the sample has a defensible connection to the population. This is especially important when using statistical methods to make claims beyond the observed data. Random sampling does not automatically make every test valid, but it makes the sampling side of the argument much clearer.
If a researcher plans to estimate population relationships using correlation analysis or regression analysis, the sample design should be described. A correlation calculated from a random sample of eligible students carries a different population interpretation from a correlation calculated only among volunteers from one club or class.
Use a different approach when depth or rare experience is central
Random sampling is not always the best choice. A qualitative study may need participants who have lived through a specific process, hold a certain role, or can describe a rare experience in detail. A random sample from the general population may produce too few relevant cases. In those situations, purposive, criterion, snowball, or theoretical sampling may fit the research question better.
The choice should follow the claim. If the study wants to estimate a population value, random sampling is often desirable. If the study wants to understand a complex experience from people who have direct knowledge of it, a smaller non-random sample may be more appropriate. What should not happen is using a non-random sample and then writing as if it were a random population sample.
How to Use Random Sampling
Using random sampling well begins before any random numbers are generated. The researcher needs to know who or what can enter the study, where those units can be found, how many are needed, and how the selection will be documented. A random procedure at the end cannot repair an unclear population or a weak frame.
The steps below describe a general process. A small classroom project may complete them quickly. A large survey may need detailed fieldwork plans, weighting procedures, and specialist software. The same logic still applies: define, list, select, contact, document, and analyse in a way that respects the design.
Step 1: Define the target population
The target population is the group the study wants to make a statement about. It should be specific enough that the reader can tell who is included and who is not. “Students” is usually too broad. “Full-time first-year undergraduate students enrolled at University X in the 2026 spring semester” is much clearer.
The definition should follow the research question. If the study asks about classroom feedback in secondary schools, the population may be teachers, pupils, classrooms, or schools, depending on the unit of analysis. A clear population definition prevents later confusion about what the findings can reasonably describe.
Step 2: Build or identify the sampling frame
The sampling frame is the practical source used for selection. It may be an enrolment list, employee roster, patient register, address file, publication database, map of field plots, or list of institutions. The researcher should check whether the frame is complete, current, and relevant.
No sampling frame is perfect in every respect. The question is whether its weaknesses are likely to affect the study. If a student list excludes part-time students, and part-time students belong to the target population, the frame is incomplete. If an address database is several years old, some households may be missing or outdated. These issues should be considered before sampling begins.
Step 3: Decide the sample size
Sample size depends on the purpose of the study, the expected variation in the data, the desired precision, the planned analysis, and practical constraints. A study estimating a simple proportion may use a different calculation from a study comparing several subgroups or fitting a regression model. Expected response rate also affects the number of people who must be invited.
Sample size is not only a larger-is-better decision. A very large sample drawn from a biased frame can still give a biased answer. A smaller sample drawn carefully may support a clearer interpretation than a larger sample collected loosely. The sample size decision should be tied to the design, not treated as a separate technical box.
Step 4: Choose the random sampling design
Once the population, frame, and sample size are clear, the researcher chooses the design. Simple random sampling may fit when the frame is complete and subgroup control is not needed. Systematic sampling may fit a long list without hidden order. Stratified random sampling may fit when subgroup representation is part of the question. Cluster or multistage sampling may fit when the population is spread across natural groups.
Step 5: Carry out the random selection
The actual selection can be done with a random number generator, statistical software, spreadsheet functions, survey software, or a verified randomisation tool. The method should be appropriate for the size and structure of the frame. For small teaching examples, a spreadsheet may be enough. For complex samples, specialised software is safer.
It is good practice to keep a record of the procedure. This may include the date of selection, the frame version, the random seed, the sampling interval, the strata used, the clusters selected, and the number of units chosen at each stage. These details allow another person to understand how the sample was produced.
Step 6: Contact selected units and track response
Random sampling does not end when units are selected. If many selected people do not respond, the final dataset may differ from the selected sample. A researcher should track how many units were selected, how many were eligible, how many were contacted, how many participated, and why some did not enter the final dataset.
Non-response is not always random. Students with heavy work schedules may respond less often to a campus survey. Patients with limited internet access may respond less often to an online questionnaire. If non-response is related to the study topic, it can affect the results. When possible, researchers compare responders and non-responders using available information.
Step 7: Analyse according to the design
The analysis should match the sampling design. A simple random sample may be analysed with standard methods if other assumptions are reasonable. Stratified, cluster, and multistage samples may need weights, design effects, adjusted standard errors, or survey analysis procedures. Treating a complex sample as if it were a simple random sample can make results look more precise than they are.
This point is especially important when the study reports confidence intervals, p-values, or model estimates. The variables being analysed, the sample design, and the planned inference all belong in the same methods section.
Report the sampling procedure clearly
The final report should let readers follow the sample from the population definition to the analysed dataset. This usually means naming the sampling frame, explaining the random procedure, giving the planned and achieved sample sizes, and showing how many units were lost through ineligibility, non-contact, refusal, or missing data.
Clear reporting also helps interpretation. A sentence saying that a study used random sampling is not enough on its own. Readers need to know whether the sample was simple, stratified, clustered, or multistage, and whether the analysis treated it that way. In student work, even a short paragraph with these details can make the methods section much stronger.
Advantages of Random Sampling
Random sampling has several advantages when the research goal is to describe or estimate features of a population. These advantages come from the chance-based selection process and from the way that process can be connected to statistical theory.
The advantages are strongest when the sampling frame is sound and fieldwork is careful. Random selection is not a magic step. It works as part of a design that also includes clear eligibility rules, a realistic sample size, a good contact procedure, and honest reporting.
It reduces researcher influence in selection
Because selection is determined by a random rule, the researcher does not decide case by case who would be convenient, interesting, cooperative, or typical. This lowers the risk that the sample quietly reflects the researcher’s preferences or field access habits.
This feature is especially useful in studies where the researcher has many possible units to choose from. Without a random rule, it is easy to drift toward familiar classes, nearby clinics, responsive participants, or records that are easiest to retrieve.
It gives a basis for estimating sampling error
Random sampling allows researchers to estimate how much a statistic might vary from sample to sample. This is the logic behind standard errors, confidence intervals, and many hypothesis tests. The sample result remains uncertain, but the uncertainty can be described in a structured way.
For example, a sample proportion of 0.42 is more informative when reported with a confidence interval. The interval tells the reader how precise the estimate is under the design and assumptions used. Without a probability-based sample, this kind of statistical interpretation becomes harder to justify.
It can improve credibility of population claims
When a study claims something about a wider population, readers naturally ask how the observed cases were chosen. A well-described random sampling design gives a stronger answer than a vague recruitment statement. It shows that the sample was not assembled only from the easiest or most visible units.
This does not mean every random sample deserves broad claims. Coverage error, non-response, measurement problems, and analysis choices still shape the result. The advantage is that random sampling gives the population claim a clearer starting structure.
It works with many statistical methods
Random sampling fits naturally with many tools used in quantitative research. It can support estimation, group comparisons, Pearson correlation, Spearman correlation, Kendall’s tau, regression models, and other procedures when the data and assumptions fit.
The sampling design does not choose the statistical method by itself. The type of variable, the research question, and the structure of the data still guide the analysis. Random sampling simply helps the researcher explain how the observed data connect to the population being discussed.
Limitations of Random Sampling
Random sampling is powerful, but it is not always easy or suitable. Its limitations are mostly practical and design-related. A chance-based procedure can only select from the units that are reachable through the frame. It can reduce selection bias, but it cannot remove every source of bias in a study.
Understanding these limits keeps random sampling from being treated as a label that automatically guarantees quality. A study can be random in selection and still be weak if the frame is poor, the response rate is low, the measurements are unclear, or the analysis ignores the sample design.
It needs a usable sampling frame
The clearest limitation is the need for a frame. If the population cannot be listed or reached through a reliable route, random sampling becomes difficult. Hidden populations, informal communities, rare experiences, or rapidly changing groups may not have a complete list from which to sample.
Even official lists can have gaps. A student register may omit recent transfers. A patient database may exclude people treated outside the system. A household list may miss temporary residents. If those missing units differ from those listed, the final sample may be biased even though the selection from the frame was random.
It can be costly or slow
Random sampling may require time to build a frame, draw the sample, contact selected units, follow up non-responders, and document the process. In large or spread-out populations, travel and administration can become substantial. Cluster or multistage designs can reduce some costs, but they add statistical complexity.
For student projects, pilot studies, small qualitative studies, or early exploration, a full probability sample may be unrealistic. In those cases, another sampling method may be acceptable if the claims stay within the limits of the design.
It does not guarantee representativeness in every sample
A random sample can still differ from the population by chance. This is sampling error. If the sample is small, the difference may be noticeable. A simple random sample may include fewer members of a small subgroup than expected, or it may produce an unusual distribution on a variable that the researcher did not control.
This does not mean the method failed. It means samples vary. Larger sample sizes, stratification, and careful planning can reduce some problems, but no single sample is a perfect miniature of the population.
It can be weakened by non-response
Random selection gives a planned sample. The final dataset depends on participation, eligibility, data quality, and follow-up. If selected units do not respond, and the non-responders differ from responders in ways related to the study, the final data may be biased.
This is why response tracking is part of sampling quality. Researchers should report the number selected, the number contacted, the number eligible, the number who participated, and the number included in the analysis. When possible, they should describe whether responders and non-responders differed on available characteristics.
It can make analysis more complex
Some random sampling designs are simple to draw but more demanding to analyse. Stratified, cluster, and multistage samples may involve unequal selection probabilities, design weights, or correlated observations within clusters. If these features are ignored, estimates may still be calculated, but their standard errors and confidence intervals may be too small or otherwise misleading.
This does not mean complex designs should be avoided. It means the sampling plan and the analysis plan should be developed together. A design that saves time in the field may require more careful statistical work later.
Conclusion
Random sampling gives researchers a structured way to select a sample from a wider population. Its central idea is simple: use chance rather than convenience or preference to decide which units enter the study. That simple idea becomes more flexible in practice, because random sampling can be simple, systematic, stratified, clustered, or multistage.
The method is especially useful when the study wants to estimate population values, compare planned subgroups, or use statistical inference from sample data. It helps researchers describe uncertainty instead of pretending that one sample result is exact. It also makes the sampling process easier for readers to inspect.
At the same time, random sampling should be handled with care. It needs a clear population, a usable sampling frame, a documented selection procedure, response tracking, and an analysis that respects the design. When those parts are kept together, random sampling becomes more than a technical step. It becomes a visible part of how the study connects limited data to a wider research claim.
FAQs on Random Sampling
What is random sampling?
Random sampling is a probability sampling method in which units are selected from a defined population or sampling frame through a chance-based procedure. Each unit has a known chance of selection, and in simple random sampling each unit has an equal chance.
What is an example of random sampling?
An example is a researcher using a random number generator to select 300 students from a complete enrolment list of 5,000 eligible students. The selected students are then invited to participate according to the study plan.
What are the main types of random sampling?
The main types are simple random sampling, systematic sampling, stratified random sampling, cluster sampling, and multistage sampling. They differ in how the population is organised and where chance is used during selection.
What is the difference between random sampling and random assignment?
Random sampling selects units from a population for inclusion in a study. Random assignment places participants who are already in the study into groups or conditions. Random sampling supports population inference, while random assignment supports comparison between study conditions.
When should researchers use random sampling?
Researchers should use random sampling when they have a defined population, a usable sampling frame, and a research question that involves estimating or comparing population values. It is especially useful for surveys and quantitative studies that rely on statistical inference.
What are the limitations of random sampling?
Random sampling can be limited by incomplete sampling frames, cost, time, non-response, and chance variation in the selected sample. It reduces selection bias but does not automatically guarantee a representative final dataset.



