Sampling methods are the procedures researchers use to choose a smaller group from a larger population. In a well-planned study, sampling is not an afterthought. It decides who enters the study, whose experiences or measurements are represented, and how far the findings can reasonably travel beyond the people who were actually observed.
This article explains what sampling methods are, how probability and non-probability approaches differ, which main types researchers use, how to compare them, and how sample size planning connects to sampling decisions.
What Are Sampling Methods?
Sampling methods are the planned procedures used to select units from a population. Those units may be people, households, schools, documents, organisations, medical records, events, images, test scores, soil samples, or any other unit that can provide data for a study.
The word “method” is useful here because sampling should be more than a convenient habit. A researcher should be able to explain how the sample was selected, why that method was appropriate, and what limits follow from it. Without that explanation, readers cannot judge how much confidence to place in the findings.
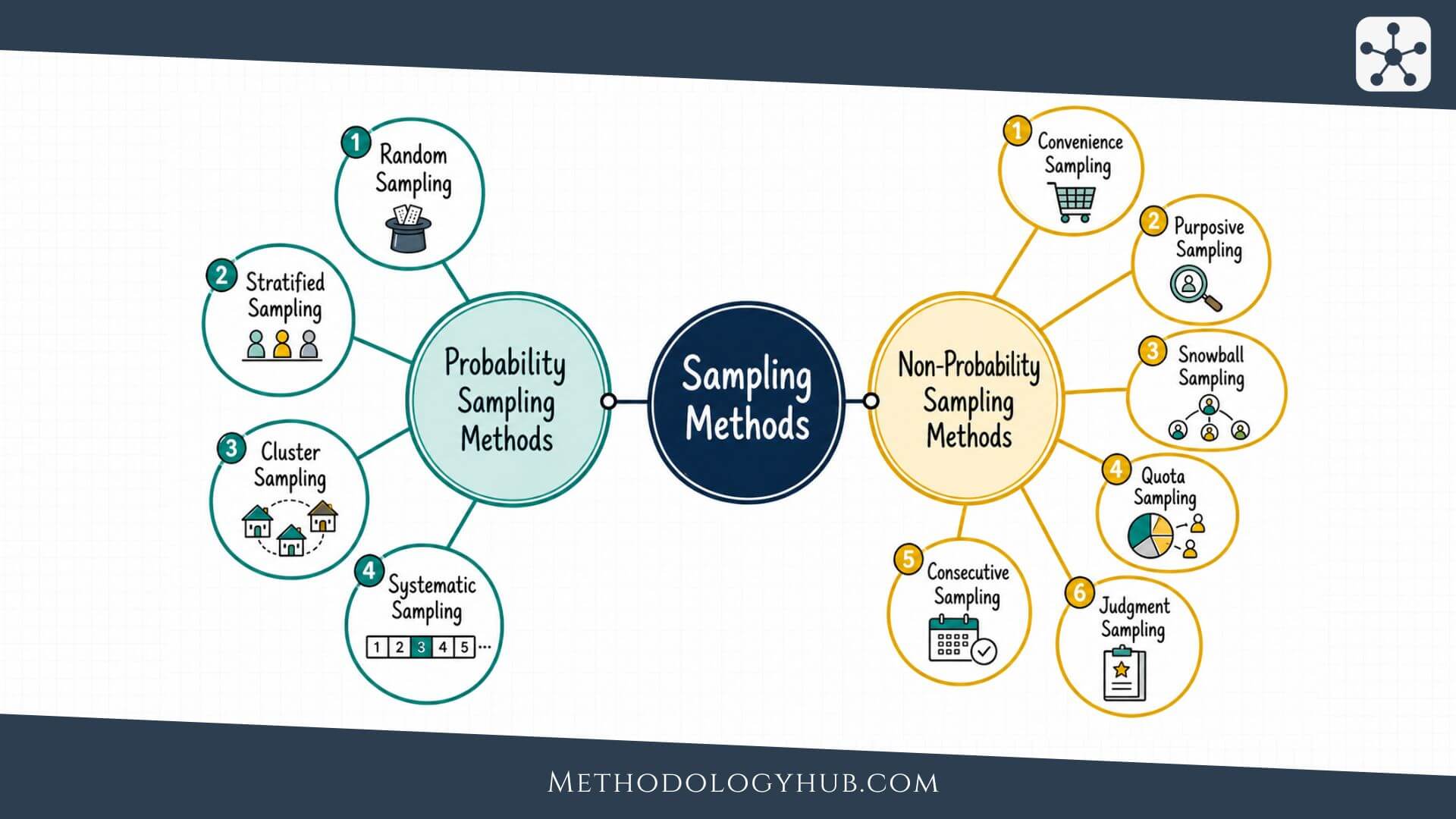
Most sampling methods fall into two broad families: probability sampling and non-probability sampling. Probability sampling uses random selection in some form. Non-probability sampling selects units without giving every member of the population a known chance of selection. Both families are used in academic research, but they support different kinds of claims.
Role of Sampling in Research
The role of sampling in research is to make data collection manageable while preserving a clear link to the study’s purpose. Researchers usually cannot observe everyone or everything. They need a smaller set of cases that can answer the question with enough credibility.
Sampling also protects the logic of the study. If the research question asks about a defined population, the sampling method should make sense for that population. If the question asks about variation between subgroups, the sample should include those subgroups in a deliberate way. If the question asks about a rare experience, the method should help locate people who have actually had that experience.
Good sampling therefore helps with three tasks at once. It narrows the field of data collection. It supports the kind of inference the study wants to make. It also makes the study more transparent, because readers can see how the evidence was gathered rather than having to guess.
Choosing the Right Sampling Method
Choosing the right sampling method begins with the research question. A question about prevalence, averages, or population-level estimates usually needs a different sampling strategy from a question about meaning, process, experience, or theory development.
Researchers also need to consider access. Some populations can be listed and sampled directly. Others cannot. Patients in a hospital ward, enrolled students, registered voters, or employees in an organisation may be reachable through a sampling frame. People with undocumented status, survivors of rare events, or members of informal networks may require a different route.
A careful sampling decision usually considers:
- the research question: what the study is trying to find out
- the target population: who or what the findings are about
- the sampling frame: whether a usable list or access route exists
- the design: whether the study is quantitative, qualitative, mixed-methods, experimental, observational, or descriptive
- the intended inference: whether the study aims for population estimates, comparison, explanation, exploration, or depth
- the available resources: time, funding, field access, staffing, and expected response rates
Resources also shape the choice. A national probability sample may produce strong population estimates, but it can be expensive and slow. A purposive interview sample may be more realistic for a small qualitative project, but the findings should not be presented as if they estimate a full population. The method and the claim must stay aligned.
There is rarely one perfect method in the abstract. There is usually a better or worse fit for a particular study. A strong methods section explains that fit plainly.
Sampling Methods in Research
Sampling methods in research connect the population a study cares about with the data a researcher can realistically collect. The population is the full group of interest. The sample is the smaller group actually studied. The sampling method is the rule or procedure used to move from one to the other.
This sounds simple, but the decision carries a great deal of methodological weight. A study may use strong measures, careful analysis, and clear writing, yet still produce weak conclusions if the sample was poorly chosen. A sample that excludes relevant groups, depends only on easy-to-reach participants, or is too small for the planned analysis can limit the whole project before data collection even begins.
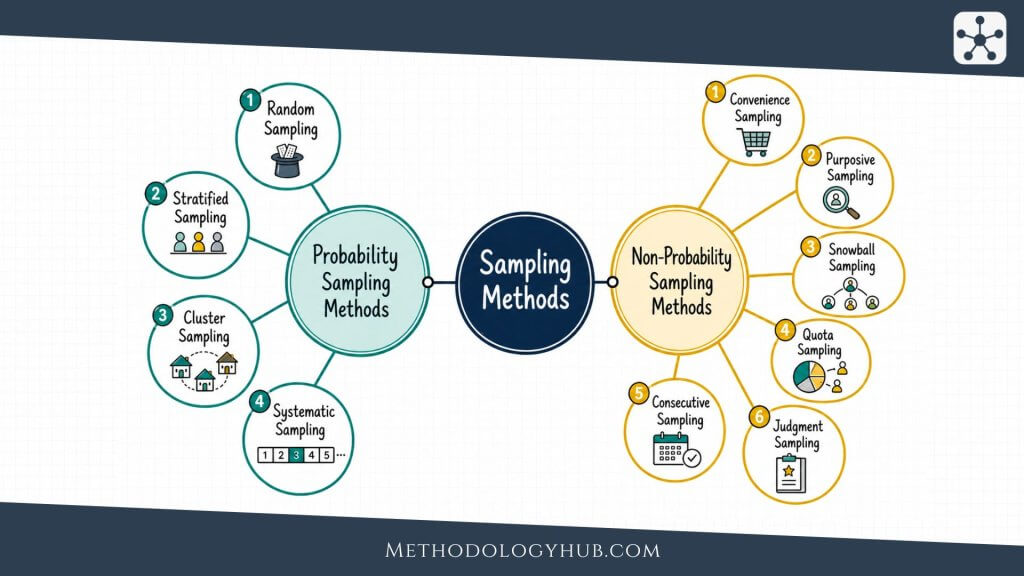
Population, sample, and sampling frame
Sampling begins with a population, but populations are often harder to define than they first appear. “Students” is too broad for most studies. Undergraduate students at one university, first-year biology students, or part-time students in public universities are clearer populations because they tell the reader who could in principle be included.
Once the population is defined, researchers need a sampling frame. This is the practical list, database, map, register, or access route from which the sample can be selected. In a school study, the sampling frame might be an enrolment list. In a household survey, it might be a list of addresses. In qualitative research, it may be a recruitment route through clinics, community groups, or professional networks.
Simple distinction: the population is the group the study wants to understand. The sampling frame is the route the researcher actually has for reaching that group.
The sampling frame rarely matches the population perfectly. Some people may be missing. Some entries may be outdated. Some groups may be easier to contact than others. This is why sampling is partly technical and partly practical. The researcher has to ask whether the available route into the population is good enough for the research purpose.
Representativeness and inference
A sample is representative when it reflects the population in the ways that are relevant to the research question. This does not mean every small detail must match perfectly. It means the sample should not be systematically tilted in a way that changes the answer.
For example, a study of student access to online learning would be weakened if it recruited only students who already use the university’s digital platform every day. Those students may have different internet access, confidence, schedules, and support than students who rarely log in. The problem is not only the number of participants. It is the way the sample was reached.
Sampling methods help researchers handle this problem deliberately. Probability sampling methods aim to give members of the population a known chance of selection. Non-probability sampling methods do not provide that same statistical basis, but they can be useful when the study is exploratory, qualitative, focused on a specific group, or dealing with a population that cannot be listed easily.
Sampling as part of research design
Sampling should be chosen with the whole design in mind. A cross-sectional survey, an interview study, a clinical trial, a case study, and an ethnographic project do not need the same kind of sample. They ask different questions and make different claims.
A survey that aims to estimate a population percentage usually needs a sampling method that supports statistical inference. An interview study that aims to understand how participants experience a process may need a smaller, more purposefully selected sample. A study of a hidden population may need chain referral techniques because a complete sampling frame does not exist.
Seen in this way, sampling is not a mechanical step after the research question. It is one of the places where the research question becomes practical. The researcher decides what kind of evidence would count, who can provide it, and how participants or cases will be selected with enough transparency for readers to judge the study.
Units of analysis and inclusion criteria
Another early sampling decision is the unit of analysis. The unit of analysis is the thing the researcher studies and later analyses. In many projects, the unit is a person. In others, it may be a household, a school, a medical record, a published article, a social media post, a classroom lesson, a court case, a blood sample, or a village.
Confusion begins when the unit of analysis and the unit of recruitment are not the same. A researcher may recruit schools but analyse students. A researcher may recruit households but analyse individual adults. A researcher may sample hospitals but analyse patient records inside those hospitals. These designs can be perfectly reasonable, but they need to be described clearly because the sampling steps happen at more than one level.
Inclusion and exclusion criteria also belong in the sampling plan. Inclusion criteria define who or what can enter the study. Exclusion criteria define who or what will be left out even if they seem close to the population. These criteria should follow from the research question, not from convenience alone.
For example, a study on first-year university adjustment might include only students in their first two semesters and exclude exchange students if their university structure is too different for comparison. A clinical records study might include adults with a confirmed diagnosis during a defined period and exclude records with missing outcome data. The point is not to make the sample look tidy after the fact. The point is to make the boundaries of the study visible before interpretation begins.
Sampling bias and response
Sampling bias occurs when the selection process systematically favours some units over others in a way that affects the results. Bias can enter through the sampling frame, recruitment method, eligibility criteria, response pattern, or fieldwork procedure.
A survey may have a good initial sampling plan but still become biased if only a narrow group responds. A study of working students, for instance, may miss students with long work hours if recruitment happens only during daytime lectures. A health survey may underrepresent people with limited digital access if invitations are sent only through an online portal. In both cases, the final sample is shaped by access and response, not only by the original sampling method.
This is why response rate and non-response analysis are part of sampling quality. A high response rate does not guarantee an unbiased sample, but a very low response rate raises questions about who is missing. When possible, researchers compare responders and non-responders on available characteristics, such as age, region, programme, clinic, or baseline status. Even a short comparison can help readers judge whether the final sample still resembles the intended one.
In qualitative research, the issue appears differently. Researchers may not aim for statistical representation, but they still need to ask whether recruitment produced a narrow set of voices. If all interviewees come from one access point, share similar backgrounds, or hold unusually strong views, that shape should be acknowledged. The sample may still be valuable, but its boundaries should be visible.
A transparent sampling section usually reports who was eligible, how people or cases were identified, how many were approached, how many participated, and why some were excluded or lost. These details keep sampling from becoming a vague statement such as “participants were recruited” and turn it into a traceable part of the design.
Probability Sampling Methods
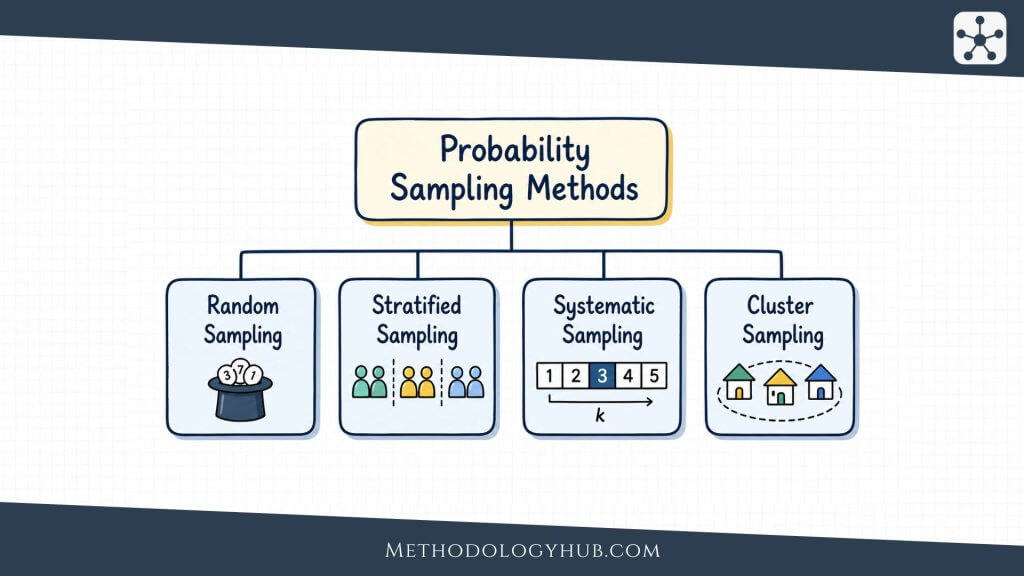
Probability sampling methods use random selection so that units in the population have a known, non-zero chance of being selected. This feature is what gives probability sampling its statistical strength. When the sampling frame is sound and the response rate is handled carefully, researchers can estimate sampling error and make more defensible claims about the wider population.
Probability sampling does not mean the sample will automatically be perfect. A poor sampling frame, low response rate, or flawed fieldwork process can still create bias. Random selection helps, but it does not rescue every problem. It works best when the researcher has a clear population, a reliable sampling frame, and a design that matches the intended analysis.
Random Sampling

Random sampling, often called simple random sampling, selects units so that each member of the sampling frame has an equal chance of being chosen. If a researcher has a complete list of 5,000 students and uses a random number generator to select 300, that is a simple random sample.
The appeal of random sampling is its clarity. The rule is easy to explain, and the logic is easy for readers to understand. Selection does not depend on the researcher’s preference, the participant’s convenience, or the order in which people appear during recruitment.
Its weakness is practical. Simple random sampling requires a full and accurate sampling frame. That is not always available. It can also produce an uneven sample by chance when the population includes small but important subgroups. For example, if international students are only a small proportion of the university population, a simple random sample may include too few of them for separate analysis.
Stratified Sampling
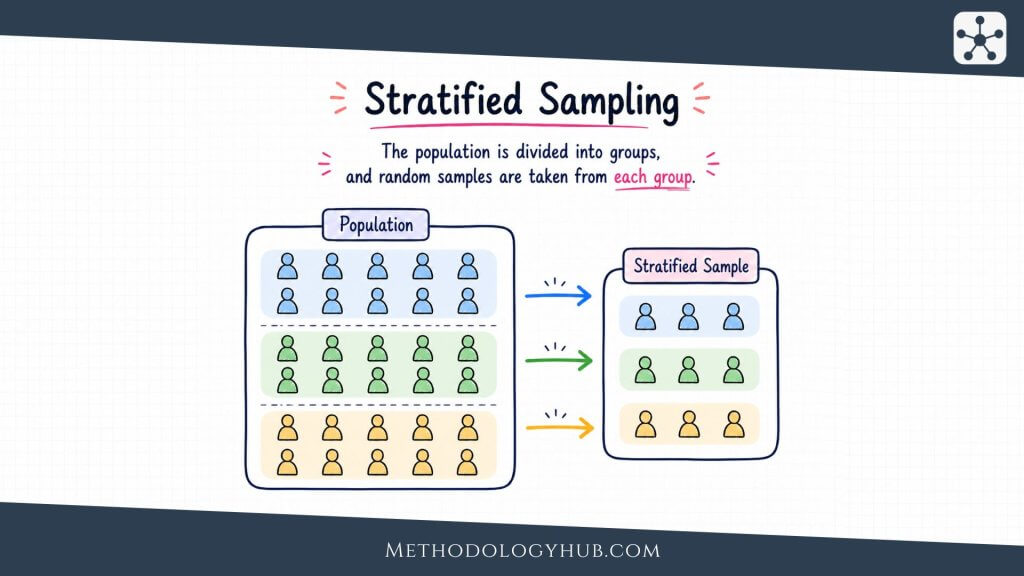
Stratified sampling divides the population into subgroups, called strata, and then samples from each stratum. The strata are usually based on variables that are relevant to the research question, such as age group, year of study, school type, region, gender, diagnosis, or professional role.
This method is useful when researchers want the sample to reflect important subgroup differences. Instead of hoping that random sampling produces enough participants in each category, stratified sampling builds that concern into the design. A researcher studying student satisfaction across faculties, for example, might sample separately from each faculty.
Stratified sampling can be proportionate or disproportionate. In proportionate stratified sampling, each subgroup appears in the sample in the same proportion as in the population. In disproportionate stratified sampling, smaller groups may be intentionally oversampled so that there are enough cases for comparison. When this happens in quantitative research, weights may be needed during analysis.
The strength of stratified sampling is control over subgroup representation. The cost is added complexity. The researcher needs good information about the population before sampling begins, and the analysis must respect how the sample was built.
Cluster Sampling
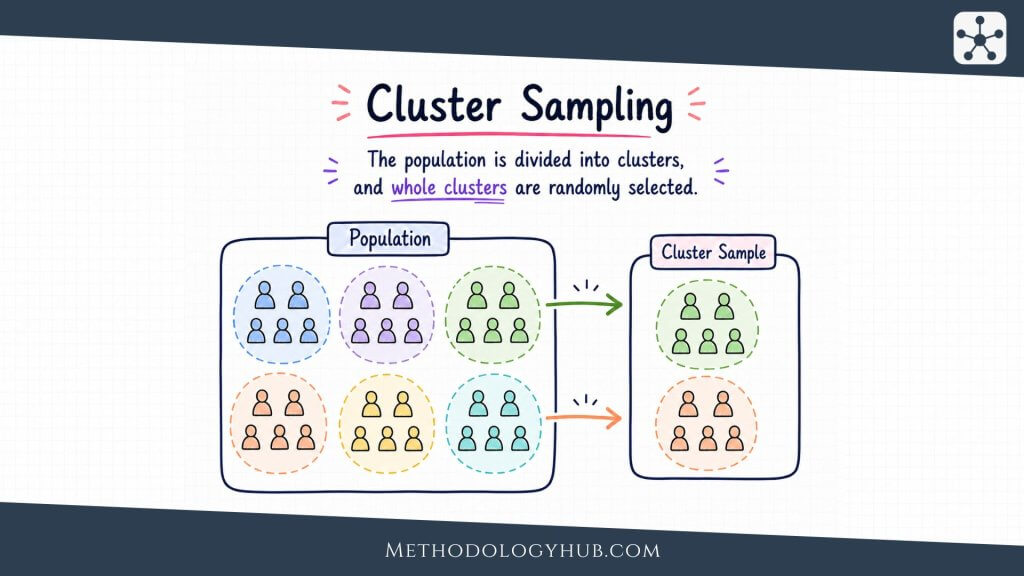
Cluster sampling selects groups, or clusters, rather than selecting individuals directly from the whole population. Clusters may be schools, classrooms, villages, hospitals, clinics, neighbourhoods, households, or other naturally occurring units. The researcher samples clusters first, then collects data from all units inside selected clusters or from a further sample within them.
This method is often used when the population is widely spread and a full list of individuals is not practical. A national education study, for example, may sample schools first and then sample students within those schools. This is usually more manageable than building one complete list of all students across the country.
The trade-off is precision. People inside the same cluster often resemble one another more than people from different clusters. Students in the same school may share teachers, facilities, neighbourhood conditions, and school policies. Because of this similarity, cluster sampling often requires a larger sample than simple random sampling to achieve the same level of precision.
Cluster sampling can be very efficient, but it needs careful analysis. Researchers should account for the clustered design instead of treating every individual as if they were selected independently from one flat list.
Systematic Sampling
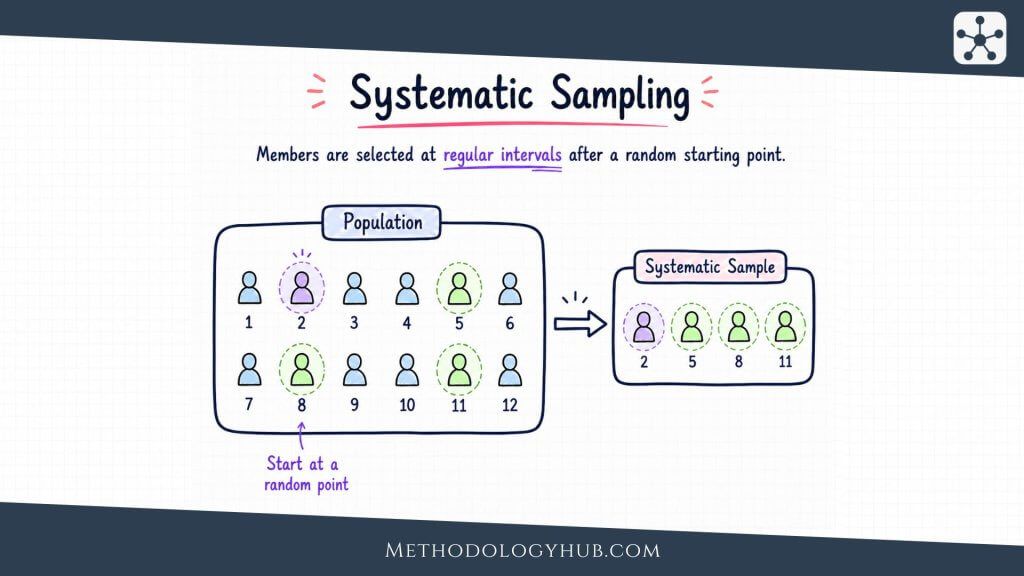
Systematic sampling selects every kth unit from an ordered sampling frame after a random starting point. If a list has 10,000 names and the researcher needs 500, the sampling interval is 20. After choosing a random start between 1 and 20, the researcher selects every 20th name.
The method is simpler to carry out than simple random sampling when working with long lists. It spreads the sample across the whole frame and can be efficient in field settings, such as selecting every nth household on a route or every nth record in a database.
The main caution is hidden order. If the list has a pattern that matches the interval, systematic sampling can introduce bias. Imagine a clinic list ordered by appointment time, where every 10th slot belongs to a particular type of appointment. Selecting every 10th record could overrepresent that group. A random start helps, but it does not remove all risks created by periodic patterns.
Systematic sampling works best when the list is complete, the order is not related to the study variables, and the researcher wants a simple probability procedure that is easy to apply consistently.
Non-Probability Sampling Methods
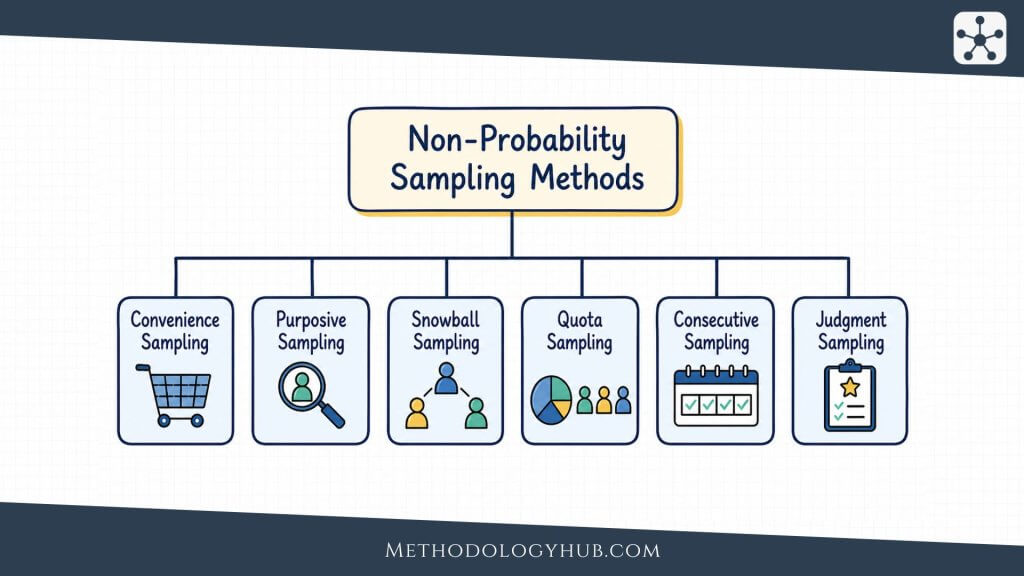
Non-probability sampling methods select units without giving every member of the population a known chance of being chosen. This means the researcher usually cannot calculate sampling error in the same way as with probability sampling. The sample may still be useful, but the conclusions need to be framed carefully.
These methods are common in qualitative research, exploratory studies, pilot work, clinical or field settings, hard-to-reach populations, and situations where a probability sample is not feasible. Their value depends on whether the selection logic fits the research purpose and whether the researcher reports that logic transparently.
The names can overlap. Judgment sampling is often treated as a form of purposive sampling, because cases are selected through informed researcher judgment. Consecutive sampling can look close to convenience sampling because it depends on accessible cases. Quota sampling can look similar to stratified sampling because it uses categories, but it does not randomly sample within those categories. These are not all the same method, and the differences affect what a study can claim.
Convenience Sampling
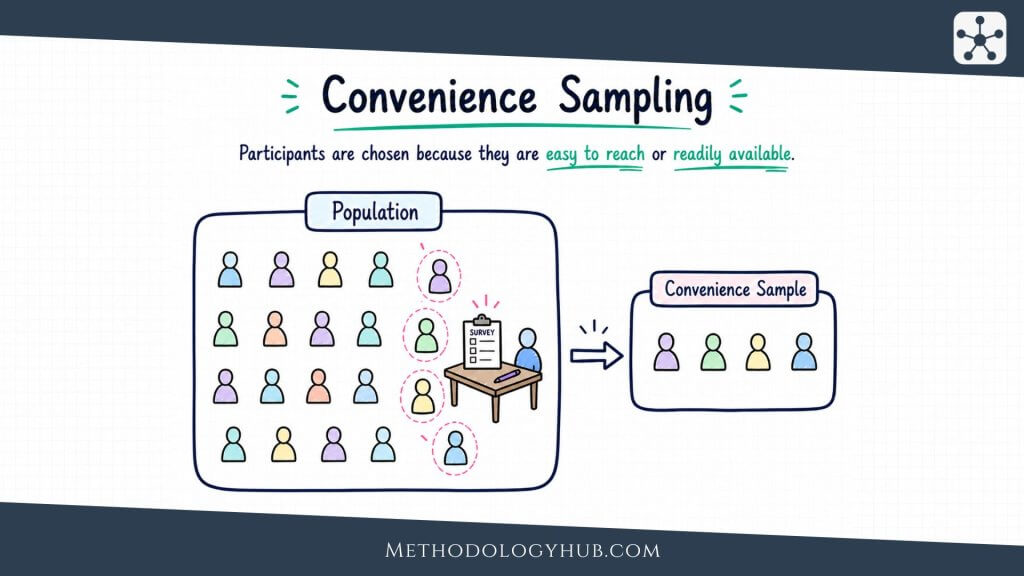
Convenience sampling selects participants or cases because they are easy to reach. Students in one class, patients attending one clinic during a data collection week, people who respond to a public survey link, or volunteers recruited through a campus poster may all form convenience samples.
The method is quick and inexpensive, which explains why it appears often in student projects and early-stage research. It can be useful for pilot testing a questionnaire, exploring whether a procedure works, or gathering preliminary evidence before a larger study.
The limitation is selection bias. People who are easy to reach may differ from those who are not. Volunteers may be more interested in the topic, more available, more confident, or more affected by the issue than non-volunteers. Because of this, convenience samples should not be described as if they represent a broader population unless there is strong evidence to support that claim.
Convenience sampling is acceptable when the study’s aims are modest and the limitations are clear. It becomes weak when the sample is treated as more representative than it is.
Quota Sampling
Quota sampling selects participants until predefined category targets are reached. The researcher first identifies categories that should appear in the sample, such as gender, age group, year of study, region, profession, or clinic type. They then recruit participants non-randomly within those categories until each quota is filled.
This method is sometimes confused with stratified sampling because both use subgroups. The difference is the selection step. Stratified sampling samples randomly within strata. Quota sampling sets subgroup targets, but participants inside each category are usually selected through convenience, field access, interviewer recruitment, or another non-random route.
Quota sampling can make a non-probability sample less lopsided than a purely convenience-based sample. For example, a researcher may decide that a student survey should include a certain number of first-year, second-year, and final-year students. That improves category coverage, but it does not remove selection bias inside each category.
The method works best when the researcher needs visible subgroup coverage but cannot implement a full probability design. Its weakness is that the sample may still overrepresent the easiest people to recruit within each quota.
Purposive Sampling
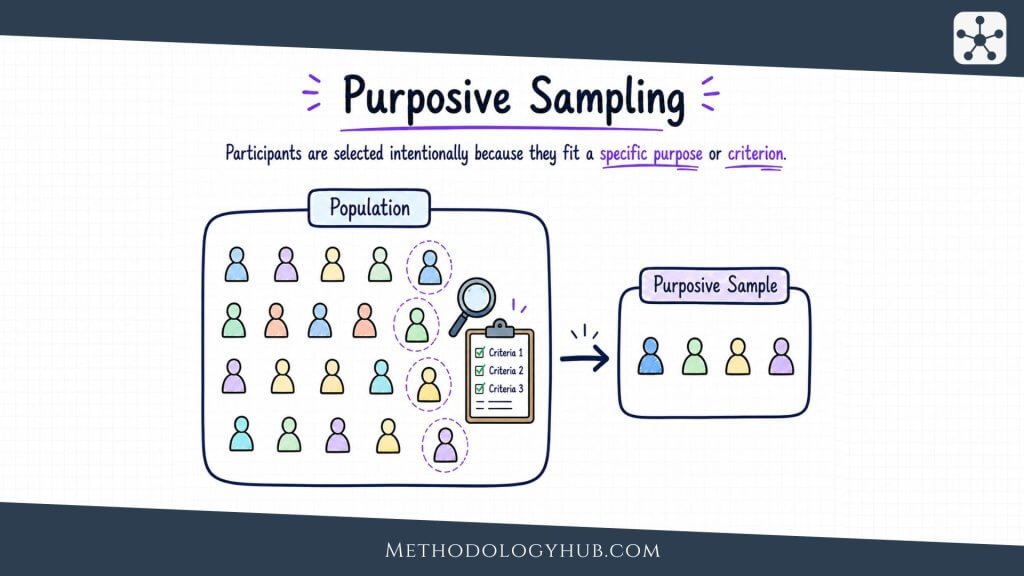
Purposive sampling, also called purposeful sampling, selects cases because they can provide information that fits the study’s purpose. Instead of trying to include whoever is easiest to reach, the researcher defines criteria and looks for participants, documents, events, or cases that meet those criteria.
This method is especially common in qualitative research. A researcher studying how first-generation students navigate postgraduate applications might deliberately recruit first-generation students at different stages of the process. A researcher studying clinical decision-making might sample professionals with different roles, years of experience, or workplace settings.
Purposive sampling can take several forms. Maximum variation sampling seeks diversity across relevant characteristics. Typical case sampling focuses on cases that reflect ordinary conditions. Criterion sampling includes cases that meet a defined condition. Expert sampling recruits people with specialised knowledge.
The strength of purposive sampling is fit. The researcher chooses participants because they can speak directly to the question. The limitation is that the sample does not support statistical generalisation. Its credibility comes from thoughtful selection, depth of evidence, and clear explanation of why those cases were chosen.
Judgment Sampling
Judgment sampling selects cases because the researcher, fieldworker, or subject expert judges them to be especially relevant for the study. It is closely related to purposive sampling and is often discussed as one of its forms. The difference is mainly emphasis. Purposive sampling starts from explicit criteria tied to the research question. Judgment sampling places more weight on the researcher’s informed decision about which cases are most useful.
For example, a researcher studying curriculum reform might deliberately choose schools that experienced the reform in unusually clear or information-rich ways. A clinical researcher might ask experienced staff to identify cases that show a particular diagnostic pathway. A document study might select policy texts judged to be central examples in a field.
The strength of judgment sampling is expert focus. It can save time and bring attention to cases that are likely to reveal important details. The limitation is subjectivity. Readers need to know who made the judgment, what criteria guided it, and why those cases were considered appropriate.
Judgment sampling should therefore be explained more carefully than a generic statement such as “cases were selected by the researcher.” The better version names the selection criteria and shows how the chosen cases connect to the research aim.
Snowball Sampling
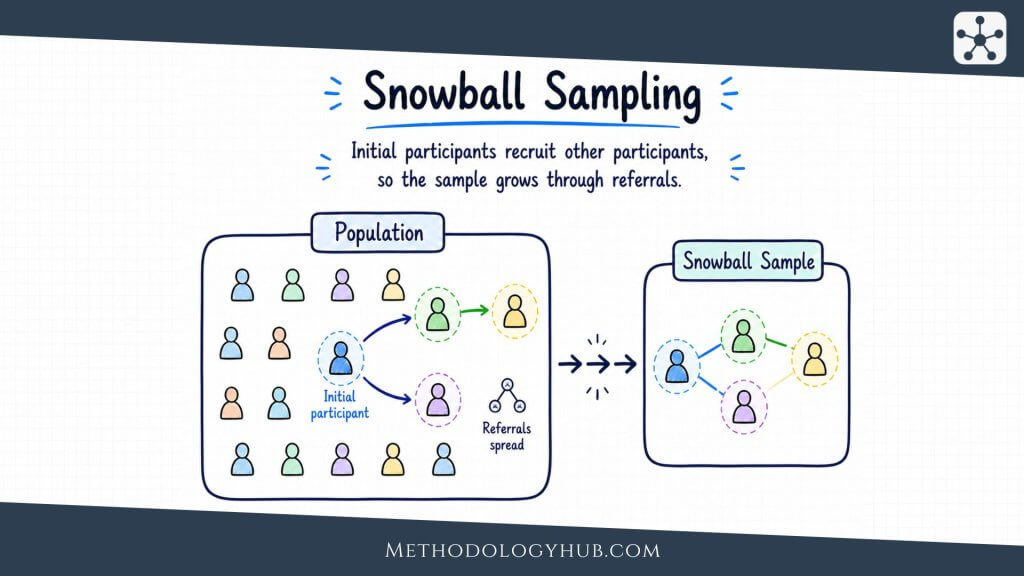
Snowball sampling uses participant referrals to reach further participants. The researcher begins with a small number of eligible participants, sometimes called seeds, and asks them to identify others who may meet the study criteria. The sample grows through social or professional links.
This method is useful when the population is difficult to identify through public lists. It may be used with hidden, dispersed, stigmatised, informal, or specialised groups. For example, researchers may use snowball sampling to reach people with rare experiences, members of informal work networks, or participants in communities where trust is needed before recruitment can begin.
The limitation is that referrals often follow existing networks. People who know one another may share characteristics, views, locations, or experiences. Some parts of the population may remain outside the referral chain. The researcher therefore needs to think carefully about seed selection and, where possible, begin with several starting points rather than one narrow network.
Snowball sampling can produce rich access, especially in qualitative research, but it should be reported honestly. The final sample reflects referral paths as well as eligibility criteria.
Consecutive Sampling
Consecutive sampling includes every eligible case that becomes available over a defined period, sequence, or recruitment window until the target sample size is reached. It is common in clinical, service, classroom, and field settings where cases appear one after another and the researcher can screen them as they arrive.
For example, a clinic-based study may include every patient who meets the inclusion criteria during a three-month period. A researcher studying records might include all eligible files opened between two dates. This is different from convenience sampling because the researcher is not simply choosing whoever is easiest at a given moment. The rule is broader: include all eligible cases that appear in sequence during the defined window.
Consecutive sampling can reduce some selection problems compared with a casual convenience sample, especially when the recruitment window is clear and consistently applied. Still, it is usually treated as non-probability sampling because not every member of the wider population has a known chance of selection.
The main limitation is timing. The sample may reflect the particular period, clinic, service, season, or access point used for recruitment. A study that recruits consecutive patients during one month may miss patterns that appear at other times.
Comparing Sampling Methods
Comparing sampling methods is less about ranking them from best to worst and more about asking what each method allows the researcher to do. A probability sample may be strong for estimating a population percentage. A purposive or judgment sample may be stronger for exploring information-rich cases. A snowball sample may be the only realistic way to reach a group that has no public list. A quota sample may help cover categories when random selection is not possible, while a consecutive sample may work well when eligible cases appear one after another in a defined setting.
The central question is fit. A sampling method fits when it supports the study’s purpose, uses an access route that can actually be implemented, and leads to conclusions that are not stronger than the sample can justify. Methods with similar names or overlapping uses still need to be separated in the methods section, because each one creates a different route into the sample.
Advantages and Disadvantages
Each sampling method brings a different balance of control, feasibility, precision, depth, and bias risk. The comparison below gives a practical overview.
| Sampling method | Main advantage | Main limitation |
|---|---|---|
| Random sampling | Clear probability logic and straightforward selection | Requires a complete and accurate sampling frame |
| Stratified sampling | Improves control over subgroup representation | Needs reliable information about strata before sampling |
| Cluster sampling | Reduces fieldwork burden across dispersed populations | Often needs larger samples and design-aware analysis |
| Systematic sampling | Easy to apply to ordered lists or field routes | Can be biased if the list has a hidden pattern |
| Convenience sampling | Fast, low-cost, and useful for pilot work | Weak basis for broad population claims |
| Quota sampling | Improves visible coverage of predefined categories | Still non-random within categories and may retain selection bias |
| Purposive sampling | Good fit for depth, relevance, and qualitative inquiry | Does not estimate population parameters statistically |
| Judgment sampling | Uses expert judgment to identify especially relevant cases | Can be subjective if selection criteria are not clearly explained |
| Snowball sampling | Can reach participants who are hard to identify directly | May overrepresent connected networks |
| Consecutive sampling | Includes all eligible cases over a defined period or sequence | May reflect the specific time, place, or service used for recruitment |
When to Use Each Method
Use random sampling when the population is clearly listed and the study needs a clean probability design. It is often a good option for surveys where the goal is to estimate a population value and subgroup control is not the main issue.
Use stratified sampling when the population contains subgroups that must be represented. This is often useful in education, public health, organisational research, and social surveys where differences between categories are part of the analysis.
Use cluster sampling when the population is spread across natural groups and direct sampling of individuals would be too costly. It is common in school surveys, household studies, large health surveys, and field research across locations.
Use systematic sampling when a list or route is available and a regular interval is practical. Before using it, check whether the order of the list could interact with the interval.
Use convenience sampling for early testing, limited projects, pilot studies, or contexts where access is very restricted. Keep the claim modest. A convenience sample can show what happened among those participants, but it usually cannot support broad statements about a population.
Use quota sampling when the study needs coverage across named categories, but random selection within those categories is not realistic. It can be useful for balancing visible characteristics in surveys, interviews, or field recruitment, as long as the non-random selection is made clear.
Use purposive sampling when the study needs information-rich cases. This is often the strongest choice for qualitative interviews, case studies, expert studies, and research where the aim is to understand variation, process, meaning, or experience.
Use judgment sampling when the researcher or an expert can identify cases that are especially relevant, typical, unusual, or theoretically useful. Because this method relies on judgment, the selection criteria should be stated plainly.
Use snowball sampling when participants are difficult to locate without referrals. Start from more than one seed when possible, and describe how the referral process shaped the sample.
Use consecutive sampling when eligible cases appear over time and the study can include all of them during a defined recruitment period. It is often useful in clinics, services, classrooms, archives, or other settings where cases arrive in sequence.
Sample size calculator
Choosing a sampling method and choosing a sample size are related decisions, but they are not the same decision. The sampling method explains how units enter the study. The sample size explains how many units are needed for the design, analysis, and desired level of precision or statistical power.
We at Methodology Hub created a free, privacy-friendly sample size calculator tool. You can use it to estimate the sample size needed for your study based on statistical inputs. It is a practical tool for planning experiments, surveys, and research designs with adequate power. Click here to use the sample size tool.
The calculator is designed for academic users who know their study question but may not know the formula name yet. You choose the kind of study you are planning, and the calculator loads the fields needed for that design. That makes the process easier to follow because the interface begins with the research situation, not with a list of formulas.
Sample size planning usually depends on inputs such as confidence level, margin of error, population size, expected proportion, effect size, statistical power, alpha level, group ratio, or outcome type. The exact inputs depend on the design. A prevalence survey does not need the same setup as a two-group comparison. A correlational study does not need the same setup as an experiment.
A calculator can support planning, but it does not replace design judgment. Researchers still need to think about non-response, missing data, exclusion criteria, subgroup analyses, clustering, measurement quality, and feasibility. In many studies, the calculated minimum should be increased to allow for expected loss of data.
Conclusion
Sampling methods shape research long before the first result is reported. They decide how participants, cases, observations, or records enter the study, and they influence what the findings can reasonably say. A strong sampling plan does not need to be complicated, but it does need to be deliberate.
Probability sampling methods, such as random, stratified, cluster, and systematic sampling, are useful when researchers need population-level estimates and have a workable sampling frame. Non-probability sampling methods, such as convenience, quota, purposive, judgment, snowball, and consecutive sampling, are useful when the study calls for practical access, category coverage, targeted cases, expert selection, qualitative depth, sequential recruitment, or hard-to-reach participants.
The most important point is alignment. The sample should fit the research question, the design, the population, and the intended claim. If the study uses a convenience sample, the conclusion should not sound like a national estimate. If the study uses quota sampling, the categories should be described without pretending the selection was random. If the study uses purposive or judgment-based interviews, the value lies in depth and relevance rather than statistical representation. If the study uses cluster sampling, the analysis should recognise the clustered design.
Sampling also connects directly to sample size. A well-chosen sample still needs enough observations for the planned analysis, and a large sample can still be weak if it was selected badly. Method and size work together. Neither one can repair the other completely.
FAQs on Sampling Methods
What are sampling methods?
Sampling methods are procedures for selecting a smaller group of units from a larger population. The units may be people, records, households, schools, organisations, documents, events, or other cases used for data collection.
What are the two main types of sampling methods?
The two main types are probability sampling and non-probability sampling. Probability sampling uses random selection and gives units a known chance of selection. Non-probability sampling does not give every unit a known chance of selection and is often used for access, depth, or exploratory purposes.
What is the difference between probability and non-probability sampling?
Probability sampling supports stronger statistical inference about a population because selection is random and selection probabilities are known. Non-probability sampling can still produce useful evidence, but the findings should be interpreted according to the selection method and study purpose.
What is random sampling?
Random sampling selects units from a sampling frame using chance. In simple random sampling, every unit has an equal chance of being selected. It is useful when the population is clearly listed and the study needs a straightforward probability design.
What is stratified sampling?
Stratified sampling divides the population into subgroups and samples from each subgroup. It is useful when the researcher wants to ensure that relevant categories, such as regions, age groups, schools, or roles, are represented in the sample.
What is cluster sampling?
Cluster sampling selects groups first, such as schools, clinics, households, or neighbourhoods. Researchers then collect data from all units inside selected clusters or from a further sample within those clusters. It is useful when a population is geographically or institutionally spread out.
What is systematic sampling?
Systematic sampling selects every kth unit from an ordered list after a random starting point. It is simple to apply, but researchers should check that the list order does not contain a pattern that could bias the sample.
What is convenience sampling?
Convenience sampling selects participants or cases because they are easy to access. It can be useful for pilot studies or limited projects, but it is usually weak for broad population claims.
What is purposive sampling?
Purposive sampling selects cases because they meet criteria connected to the research question. It is common in qualitative research, expert studies, case studies, and projects that need information-rich participants rather than a statistically representative sample.
What is snowball sampling?
Snowball sampling begins with eligible participants and uses their referrals to reach others. It is useful for hidden or hard-to-access populations, but it can overrepresent connected networks if the referral paths are narrow.
What is quota sampling?
Quota sampling sets target numbers for specific categories and then recruits participants non-randomly until each target is filled. It is different from stratified sampling because selection inside the categories is not random.
What is judgment sampling?
Judgment sampling selects cases based on the informed judgment of the researcher, fieldworker, or expert. It is often treated as a form of purposive sampling, but it should still explain who made the judgment and what criteria guided selection.
What is consecutive sampling?
Consecutive sampling includes every eligible case that appears during a defined period, sequence, or recruitment window until the sample is complete. It is common in clinical, service, classroom, and archive-based studies.
Are purposive sampling and judgment sampling the same?
They are closely related, and judgment sampling is often described as a subtype of purposive sampling. The distinction is that purposive sampling usually begins with explicit criteria tied to the research question, while judgment sampling emphasizes the researcher’s or expert’s decision about which cases are most useful.
How do I choose a sampling method?
Start with the research question, then define the population, identify the sampling frame or access route, decide what kind of inference you want to make, and check your resources. The method should fit the claim. Population estimates usually need probability sampling, while exploratory, quota-based, expert-selected, sequential, or qualitative studies may use non-probability methods.



