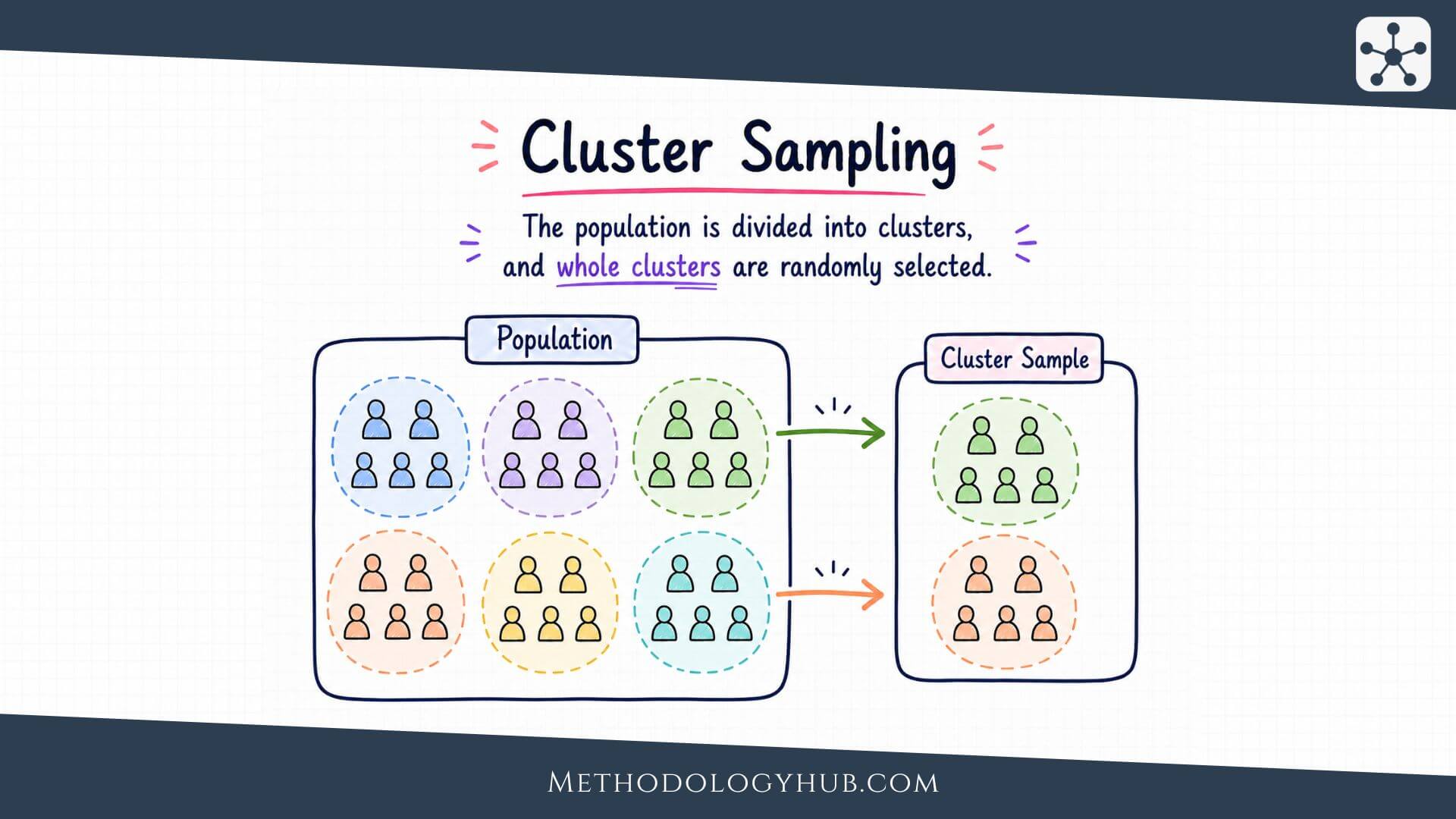
Cluster sampling is a probability-based sampling method in which researchers select groups first, rather than selecting every person, record, household, school, clinic, or observation directly from one long list. These groups are called clusters. Once clusters have been selected, the researcher collects data from all eligible units inside them or samples further within them.
This article explains what cluster sampling is, how it works in research, which main types are used, when it fits a study, how to carry it out, and how its advantages and limitations affect interpretation.
What Is Cluster Sampling?
Cluster sampling is a probability sampling method in which the population is divided into naturally occurring groups, and a random sample of those groups is selected. The groups may be schools, classrooms, villages, neighbourhoods, clinics, hospitals, households, work sites, census blocks, laboratories, or field plots. The exact form depends on the study, but the logic is the same: the researcher samples clusters first.
The method is useful when a complete list of individual units is hard to build, but a list of groups is available. A researcher may not have one list of every pupil in a large region, for example, but may have a list of schools. Instead of trying to list every pupil at the start, the researcher can randomly select schools and then collect data from pupils inside those selected schools.
Cluster sampling definition
Cluster sampling means selecting groups from a defined population through a random procedure, then collecting data from all units inside the selected groups or from a further sample within those groups. The clusters should be part of the population structure before the study begins. They are not categories created only for analysis after the data have been collected.
This point makes the method easier to understand. In a school survey, schools are clusters because pupils are already grouped inside schools. In a household survey, neighbourhood blocks may be clusters because households are already located inside blocks. In an environmental study, field plots may be clusters because observations are collected within physical areas.
Clusters and elements
A cluster is the group selected at the first stage of sampling. An element is the smaller unit that provides the final data. In a study of pupils, a school may be the cluster and a pupil may be the element. In a health records study, a clinic may be the cluster and a patient record may be the element. In a household survey, a village may be the cluster and an adult resident may be the element.
The distinction is useful because a study may sample at one level and analyse at another. A researcher can randomly select classrooms, but the final dataset may contain student test scores. That is not a problem, as long as the sampling plan and the analysis both recognise the clustered structure.
Cluster sampling and probability sampling
Cluster sampling belongs to the probability sampling family because chance is used to select clusters, and often to select elements within selected clusters. It is therefore different from convenience sampling, where researchers choose units mainly because they are easy to reach, and from purposive sampling, where units are selected because they fit a study purpose.
The random part of cluster sampling does not remove every problem. A weak list of clusters, low response within selected clusters, or an analysis that ignores clustering can still limit the study. The strength of the method is that the selection route can be described and connected to probability, rather than being left to informal access.
Cluster Sampling in Research
Cluster sampling in research usually appears when the population is spread across institutions, locations, or other natural groupings. It is common in education, public health, household surveys, environmental studies, social research, and administrative records research. The method turns a large selection problem into a more manageable sequence of decisions.
Imagine a researcher studying reading habits among pupils in a large district. A simple random sample of pupils would require a full list of all eligible pupils, contact details, permissions, and a way to reach pupils across many schools. A cluster sample begins differently. The researcher lists schools, randomly selects a number of schools, and then collects data from pupils in those schools or from a random sample of pupils inside them.
The population still comes first
Cluster sampling does not begin with the clusters. It begins with the population the study wants to describe. The researcher should first decide whether the population is all pupils in a district, all clinics in a region, all households in a city, all patients treated during a defined period, or all plots in a field area. Only after that does the researcher decide which clusters can provide access to that population.
The cluster frame
The cluster frame is the list or map of clusters from which selection occurs. It might be a list of schools, a register of clinics, a map of neighbourhood blocks, a list of villages, or a set of numbered field plots. It does not have to list every individual element at the start, but it should list the clusters that cover the target population as well as possible.
A frame can create problems if some clusters are missing or outdated. If a clinic list excludes small community clinics, patients from those clinics cannot be selected. If a school list includes schools that have closed, the selection procedure may waste effort and reduce coverage. These practical details shape the final sample, even when the random selection itself is done correctly.
Planning note: cluster sampling is strongest when the list of clusters matches the population closely and the researcher can explain what happens inside selected clusters.
Natural grouping and similarity
Clusters are usually chosen because they are practical groupings, not because they are statistically ideal. That practicality comes with a trade-off. People or observations inside the same cluster often resemble one another. Pupils in one school may share teachers, schedules, local conditions, and school policies. Patients in one clinic may share service routines. Households in one village may share local infrastructure and environment.
This similarity is called intracluster correlation. The term sounds technical, but the idea is simple. When units inside a cluster are alike, each new unit from the same cluster may add less new information than a unit from a different cluster. A sample of 300 pupils from 10 schools may therefore be less precise than a simple random sample of 300 pupils spread across the full district.
Cluster sampling and fieldwork
The practical attraction of cluster sampling is that it can reduce travel, listing, and administration. A field team may visit selected villages rather than travel to isolated households across an entire region. A school study may schedule data collection in selected schools instead of contacting individual pupils one by one. A health survey may work through selected clinics before sampling records or patients inside them.
The method does not make fieldwork simple in every case. Permission may be needed from cluster-level gatekeepers, such as school principals, clinic managers, or local administrators. Non-response can occur at both cluster and element level. A selected school may decline, and some pupils within participating schools may also not take part. These layers should be documented.
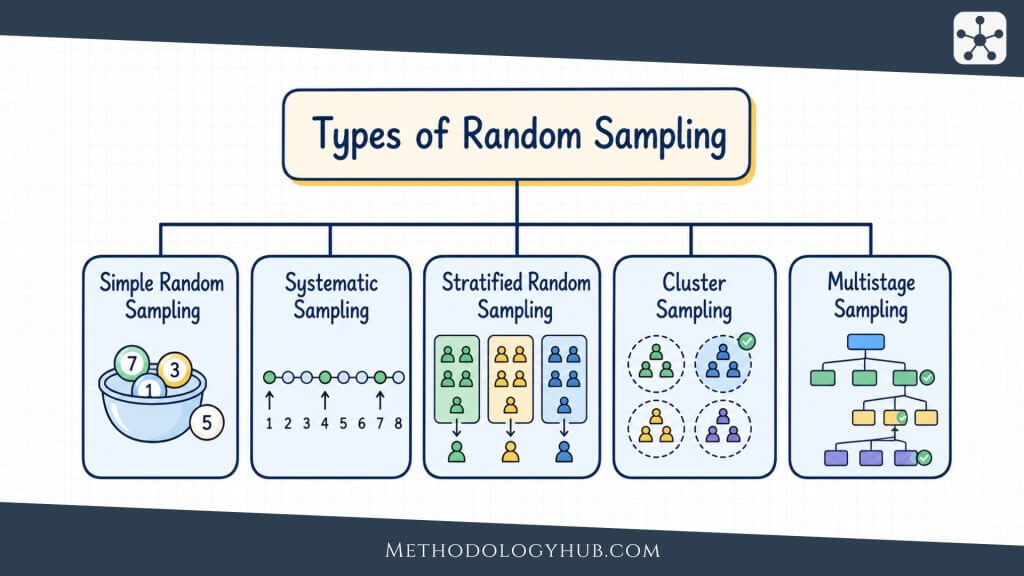
Main Types of Cluster Sampling
Cluster sampling is not one fixed procedure. The researcher may select clusters and include every element inside them, or may select clusters and then sample again within those clusters. Larger studies may use several stages, while smaller studies may use a simpler one-stage design. The choice depends on the research question, the available frame, the size of clusters, and the resources available for data collection.
One-stage cluster sampling
In one-stage cluster sampling, the researcher randomly selects clusters and includes every eligible element inside each selected cluster. A study might randomly select 20 classrooms and survey every pupil in those classrooms. A household survey might randomly select 30 blocks and visit every household in those blocks.
This design is easy to explain and can work well when clusters are not too large. It becomes harder when selected clusters contain many elements. Surveying every pupil in selected schools may be realistic if the schools are small. It may be unrealistic if some schools contain thousands of pupils.
Two-stage cluster sampling
In two-stage cluster sampling, the researcher randomly selects clusters first and then randomly selects elements within those clusters. A public health study may select clinics first and then select patient records within each clinic. An education study may select schools first and then select pupils within each selected school.
This approach often gives the researcher more control over the final workload. It can also reduce the problem of very large clusters dominating the sample. The researcher should still explain both stages: how clusters were selected and how elements were selected inside them.
Multistage cluster sampling
Multistage cluster sampling uses random selection across more than two levels. A national survey may select regions, then districts within regions, then schools within districts, then pupils within schools. Each stage narrows the field while keeping chance in the selection route.
This design is common in large surveys because the population may be too wide to handle in one step. It is also more complex to report and analyse. The methods section should tell the reader what was selected at each stage, what frame was used at that stage, and how many units moved forward to the next stage.
Probability proportional to size sampling
Clusters often differ in size. One school may have 200 pupils and another may have 2,000. One clinic may treat a small number of patients and another may serve a large region. If clusters are selected with equal probability, small clusters and large clusters have the same chance of entering the first stage, even though they contain different numbers of elements.
Probability proportional to size sampling, often shortened to PPS, handles this by giving larger clusters a higher chance of selection. The goal is not to give large clusters special treatment. It is to make the element-level selection probabilities easier to manage when cluster sizes differ. PPS designs should be planned carefully because they may require accurate size information before sampling begins.
Stratified cluster sampling
Cluster sampling can also be combined with stratified sampling. In that case, clusters are first divided into strata, and then clusters are sampled within each stratum. A school survey might divide schools by region or school level before sampling schools within each category. A clinic study might sample clinics separately from urban and rural areas.
This can improve planned coverage of important categories, but it adds another layer to the design. The researcher should explain both the strata and the cluster selection. If the analysis estimates population values, weights may be needed when probabilities differ across strata or stages.
| Type | How it works | Good fit |
|---|---|---|
| One-stage cluster sampling | Select clusters and include all eligible elements inside them. | Clusters are moderate in size and full coverage is realistic. |
| Two-stage cluster sampling | Select clusters first, then select elements inside selected clusters. | Clusters are large or the final workload needs control. |
| Multistage cluster sampling | Use random selection across several nested levels. | Large, layered, or geographically spread populations. |
| PPS cluster sampling | Select clusters with probabilities linked to cluster size. | Clusters differ strongly in size and size data are available. |
When to Use Cluster Sampling?
Cluster sampling is most suitable when the population is naturally grouped and direct sampling of individual units would be difficult, expensive, or incomplete. It is often chosen because the researcher can list clusters more easily than individuals, or because data collection is easier when observations are gathered inside selected settings.
Use it when an individual list is not practical
A complete list of individual units is often hard to obtain. A researcher may not have one accurate list of all households in a region, all pupils across many schools, all patients across multiple facilities, or all observations across a wide field area. A cluster frame may be more realistic. Schools, villages, clinics, blocks, or plots can often be listed even when individuals cannot.
This does not mean the researcher can ignore individuals. In a two-stage design, a list of elements is still needed inside selected clusters. The difference is that the list is built only for selected clusters, not for the whole population at the start.
Use it when the population is spread out
Cluster sampling fits studies where units are scattered across space. A household survey across many villages, a school survey across a district, or a field study across a wide environmental area may become too demanding if each unit is selected separately from the whole region. Sampling clusters can reduce travel and help the fieldwork follow a clearer route.
The saving is practical rather than magical. Fewer travel routes and fewer contact points can make data collection easier, but the study may need more total observations to reach the same precision as a simple random sample. The design decision should balance fieldwork effort and statistical precision.
Use it when data collection happens inside institutions or sites
Many studies collect data inside settings that already organise people or records. Schools organise pupils, clinics organise patient visits, courts organise cases, and laboratories organise samples. In these situations, sampling clusters can match the way access is arranged. The researcher may need permission and scheduling at the cluster level before reaching individuals.
For example, a study of teaching practices may need to work through schools because lessons, timetables, and permissions are organised there. A study of medical record quality may need to work through clinics because records are stored inside those facilities. Cluster sampling fits this structure more naturally than pretending that all individual units can be reached independently.
Use a different method when clusters are too similar or too few
Cluster sampling is less attractive when only a small number of clusters can be sampled or when clusters are very different from one another in ways related to the outcome. If a study samples only two schools, for example, it becomes difficult to separate school-level differences from the wider pattern. The study may still be useful as a local description, but it gives a weak basis for broader population estimates.
If subgroup representation is the main concern, stratified sampling may be a better choice. If there is a complete individual list and travel is not a concern, simple random sampling may give more precision with the same number of observations. If the population is ordered in a usable list, systematic sampling may be simpler.
How to Use Cluster Sampling
Using cluster sampling well begins before any clusters are selected. The researcher needs to define the population, decide what counts as a cluster, check the cluster frame, choose the number of stages, and plan an analysis that matches the design. A random selection step cannot repair an unclear population or a poor frame.
Step 1: Define the target population
The target population is the full group the study wants to describe. It should be specific enough that readers can tell who is included and who is not. “Pupils” is too broad for most studies. “Pupils enrolled in public secondary schools in District X during the 2026 school year” gives clearer boundaries.
The definition also identifies the unit of analysis. A study may analyse pupils, classrooms, schools, households, patients, records, or environmental measurements. Cluster sampling is easiest to report when the researcher separates the population, cluster, and element from the start.
Step 2: Decide what the clusters are
The clusters should be natural or operational groups that cover the population. In an education study, clusters may be schools or classrooms. In a household study, they may be blocks, villages, or enumeration areas. In a health study, they may be clinics, wards, hospitals, or appointment sessions.
The choice should follow access and analysis. Schools may be the right clusters if permission and data collection happen through schools. Classrooms may be better if the study focuses on classroom teaching. Villages may fit a household survey if field teams work village by village.
Step 3: Build or obtain the cluster frame
The cluster frame is the list, register, map, or database used for random selection. The researcher should check whether it is complete, current, and relevant. If cluster size will affect the design, the frame may also need size information, such as number of pupils per school or households per village.
Frame problems should be documented. If some clusters are excluded because they cannot be reached, are too small, or have missing records, that decision affects the population the study can describe. It is better to report such boundaries plainly than to hide them behind a broad label.
Step 4: Choose the cluster sampling design
The researcher now decides whether the study will use a one-stage, two-stage, multistage, PPS, or stratified cluster design. A one-stage design may work when selected clusters are small enough to include fully. A two-stage design may work when clusters are large and the researcher needs to sample within them. A multistage design may be needed when the population is layered across regions, districts, institutions, and individuals.
Step 5: Select clusters randomly
The selection can be done with statistical software, a spreadsheet, survey software, or a random number generator. The method should be documented. For example, a researcher might report that 25 schools were selected from a list of 180 eligible schools using a computer-generated random sample.
If PPS sampling is used, the researcher should explain how cluster sizes were measured and how probabilities were assigned. If stratification is used, the researcher should report how clusters were divided into strata before selection.
Step 6: Select or include elements inside clusters
In a one-stage design, every eligible element inside each selected cluster is included. In a two-stage or multistage design, the researcher samples elements within selected clusters. This second-stage sampling should also use a clear rule, especially if the study makes population-level claims.
At this stage, inclusion criteria become practical. The researcher decides which pupils, households, records, visits, or observations count as eligible inside selected clusters. Clear criteria prevent the final sample from shifting quietly during fieldwork.
Step 7: Collect, document, and analyse with the design in view
Cluster sampling should remain visible after selection. The researcher should track how many clusters were selected, how many participated, how many elements were eligible inside each cluster, how many completed data collection, and what happened to missing or excluded units. These details help readers judge the final sample.
Analysis should also match the design. Standard errors, confidence intervals, and tests may need to account for clustering. If selection probabilities differ, weights may be needed. If the study uses statistical analysis to make population claims, the sampling design should not disappear at the analysis stage.
Cluster Sampling Example
A concrete example shows how the pieces fit together. Suppose a researcher wants to estimate the average weekly reading time of pupils in public secondary schools in one district. The target population is all pupils enrolled in those schools during the school year. The element is the pupil. The cluster is the school.
A simple random sample of pupils would require one complete pupil list across the whole district. If that list is not available, the researcher may use a cluster design. A list of public secondary schools is available from the district office. The list includes each school name and the number of enrolled pupils. This becomes the cluster frame.
Planning the design
The researcher decides to use two-stage cluster sampling. First, schools will be randomly selected. Second, pupils will be randomly selected inside each selected school. Because schools vary in size, the researcher considers PPS selection, so larger schools have a higher chance of being selected at the first stage. Inside selected schools, a fixed number of pupils will be sampled from enrolment lists.
This design avoids building one pupil list for the entire district. The researcher only needs pupil lists from the selected schools. It also prevents the study from surveying every pupil in very large schools, which would make data collection uneven and slow.
Carrying out the selection
The district has 120 eligible public secondary schools. The researcher selects 24 schools using a probability proportional to size procedure. Each selected school is contacted. In schools that agree to participate, the researcher obtains a current enrolment list and randomly selects 30 pupils. If a selected pupil is absent or does not have consent, the researcher follows the pre-planned replacement or non-response rule.
At the end of fieldwork, the researcher reports how many schools were selected, how many participated, how many pupils were selected in each participating school, and how many pupils completed the survey. The method section also states that the analysis used the school cluster variable and the sampling weights created from the selection probabilities.
Reading the result
Suppose the estimated average reading time is 4.6 hours per week. That number is not read as a perfect population value. It is a sample-based estimate. Because pupils were sampled within schools, and pupils within the same school may be similar, the confidence interval should account for clustering.
If the analysis ignored clustering and treated all pupils as if they were independently selected from one flat list, the uncertainty would likely be too small. The result might look more precise than the design supports. A design-aware analysis gives a more honest reading of the estimate.
Example in one sentence: the researcher selected schools first, selected pupils inside those schools, and then analysed the pupil data while keeping the school-level clustering visible.
Cluster Sampling vs Stratified Sampling
Cluster sampling and stratified sampling are often confused because both divide a population into groups before selection. The difference is in what those groups are meant to do. Stratified sampling uses groups to improve representation of categories. Cluster sampling uses groups as practical sampling units.
In stratified sampling, the researcher divides the population into strata such as age groups, school levels, regions, or programme types, then samples within each stratum. The strata are usually chosen because they are relevant to comparison or representation. The researcher wants each stratum to appear in the sample in a planned way.
In cluster sampling, the groups are usually selected because they are practical containers for elements. Schools contain pupils. Clinics contain patient records. Villages contain households. The researcher selects some clusters and then measures all or some elements inside them.
How the groups differ
Strata are usually designed to be internally similar for a characteristic the researcher cares about. If the strata are school levels, pupils within the same level share that category. Cluster sampling works differently. A cluster should ideally contain a mix of elements, at least for the variables being estimated. A selected school, for example, may contain pupils with different reading habits, backgrounds, and scores.
This difference changes interpretation. Stratified sampling often improves precision when strata are internally similar and differ from one another. Cluster sampling often reduces precision because elements inside the same cluster resemble one another. That is the price of making fieldwork more manageable.
Example of the difference
Suppose a university researcher wants to study undergraduate study time. If the researcher divides all students into first-year, second-year, and final-year groups and samples from each group, that is stratified sampling. The groups are used to ensure planned representation across years of study.
If the researcher randomly selects tutorial groups and surveys students inside those selected tutorial groups, that is cluster sampling. The tutorial group is used as the practical route to reach students. The researcher may not be mainly interested in comparing tutorial groups; they are a sampling route.
| Aspect | Cluster sampling | Stratified sampling |
|---|---|---|
| Purpose of groups | Groups are sampled as practical units. | Groups ensure planned category representation. |
| Typical groups | Schools, clinics, villages, blocks, households, plots. | Age groups, regions, school levels, programmes, categories. |
| Selection | Select clusters, then include or sample elements inside them. | Select elements within each stratum. |
| Usual trade-off | Practical fieldwork, but often lower precision. | Better subgroup control, but requires stratum information. |
Cluster sampling can be combined with stratification
The two methods are not opposites in every design. A study can stratify clusters and then sample clusters within each stratum. For example, a researcher may divide schools by region and then randomly select schools within each region. This is a stratified cluster sample. It uses strata for planned coverage and clusters for practical access.
When methods are combined, reporting becomes especially important. The reader should be able to see which grouping was used for representation, which grouping was sampled as a cluster, and how selection probabilities were handled.
Advantages of Cluster Sampling
Cluster sampling is often chosen because it makes research possible when a direct individual sample would be too difficult to organise. Its advantages are mostly practical, but they also affect how clearly a study can be designed and reported. The method gives the researcher a route into large, spread-out, or institutionally organised populations.
It can reduce listing work
In many studies, building a complete list of individual elements is the hardest part of sampling. Cluster sampling can reduce that burden. Instead of listing every pupil, patient, household, or observation in the entire population, the researcher lists clusters first. Individual lists are then needed only inside selected clusters, if the design has a second stage.
This is especially useful when individual lists are held locally. A district office may have a list of schools but not one merged list of every pupil. Clinics may each have their own record systems. Villages may have household information locally, but not in one central file. Cluster sampling can work with that structure.
It can make fieldwork more manageable
Cluster sampling can reduce travel and coordination because data collection happens in selected locations or institutions. A field team can visit selected villages, selected schools, or selected clinics rather than spread effort thinly across the whole population. This can make training, supervision, scheduling, and quality checks easier.
For small research teams, this advantage can make the difference between a feasible design and an unrealistic one. A student research project, for example, may not be able to visit dozens of distant sites. A cluster design can keep the sample connected to probability while still respecting fieldwork limits.
It works well with naturally organised data
Some data are already organised inside clusters. School records are stored by school. Clinic records are stored by clinic. Household data are collected by neighbourhood or village. Environmental measurements may be taken by site or plot. Cluster sampling fits these structures rather than forcing the researcher to flatten the population into one individual list too early.
It can support large surveys
Many large surveys use cluster or multistage designs because direct sampling from one individual frame is not realistic. A national study may need to move from regions to districts to households or from districts to schools to pupils. Each stage reduces the fieldwork problem while keeping a documented sampling route.
Limitations of Cluster Sampling
Cluster sampling is useful, but it has limits that should be visible in the study report. The most important limitation is that units inside the same cluster often resemble one another. This makes a cluster sample less statistically efficient than a simple random sample with the same number of elements, unless the intracluster similarity is very low.
It often reduces precision
When elements inside a cluster are similar, the sample contains less independent information than the raw number of observations suggests. A study with 600 pupils from 10 schools may not carry the same precision as 600 pupils selected independently across the district. The pupils from the same school may share teachers, policies, local resources, and peer conditions.
This does not mean cluster sampling is poor. It means the sample size should be planned with clustering in view. Researchers often need more clusters or more total observations than they would need under simple random sampling.
It can produce unequal selection probabilities
Cluster sizes often differ. If all selected clusters are included fully, people in small clusters may have different chances of selection from people in large clusters. In two-stage designs, the final selection probability depends on both the probability of selecting the cluster and the probability of selecting the element inside that cluster.
When selection probabilities differ, weights may be needed for population estimates. Weighting is not a decorative technical step. It helps the analysis reflect how the sample was drawn.
It needs enough clusters
A cluster sample with very few clusters is usually weak for population inference. If a study includes many pupils but only two schools, the result may be heavily shaped by those two schools. Adding more pupils inside the same schools may not solve the problem because the design still has very little cluster-level spread.
In many cluster designs, increasing the number of clusters gives more useful information than adding many more elements to a small number of clusters. The best balance depends on costs, cluster size, intracluster similarity, and the planned analysis.
Design note: in cluster sampling, a larger total number of individuals does not automatically mean a stronger sample if most of them come from only a few clusters.
It can be affected by cluster-level non-response
Non-response can happen at more than one level. A selected school may decline to participate, a selected clinic may be unable to provide records, or a selected village may be inaccessible during the field period. Then individual non-response may occur inside participating clusters.
Cluster-level non-response can be especially serious because an entire group drops out. Replacement should not be casual. If replacement clusters are used, the rule should be planned in advance and reported. If replacements are not used, the researcher should describe the loss and consider how it may affect the final sample.
It requires design-aware analysis
Ordinary analysis procedures often assume that observations are independent. In cluster sampling, that assumption may not hold because observations inside the same cluster can be related. Standard errors may be too small if clustering is ignored, which can affect confidence intervals and hypothesis testing.
Design-aware analysis does not have to be mysterious. Many statistical packages allow researchers to specify clusters, strata, and weights. The main point is to keep the sample design visible when estimating uncertainty.
Cluster Sampling and Statistical Analysis
Cluster sampling affects the statistical analysis because it changes how information enters the dataset. In a simple random sample, each observation is usually treated as if it were selected independently from the same frame. In a cluster sample, observations from the same group may be related. This affects standard errors, confidence intervals, p-values, and sometimes weighting.
Intracluster correlation
Intracluster correlation describes how similar elements are within the same cluster. If pupils within the same school are very similar in reading time, the intracluster correlation is higher. If pupils within the same school are no more similar than pupils from different schools, it is near zero.
Higher intracluster correlation means that each additional element from the same cluster adds less new information. This is why cluster sampling often benefits from sampling more clusters rather than taking many elements from only a few clusters.
Design effect
The design effect describes how much the sampling design changes the variance of an estimate compared with a simple random sample of the same size. In cluster sampling, the design effect is often greater than 1 because clustering increases uncertainty. A design effect of 2 would mean the estimate has about twice the variance it would have under a simple random sample, under the assumptions used.
For beginners, the practical reading is enough: cluster sampling usually needs a larger sample than simple random sampling to reach the same precision. The extra sample size is not waste. It compensates for the fact that observations inside clusters are partly redundant.
Weights
Weights may be needed when units have different chances of selection. In cluster sampling, unequal probabilities can arise when clusters differ in size, when PPS sampling is used, when different numbers of elements are selected inside clusters, or when response adjustments are applied.
Weights help estimates reflect the target population rather than only the achieved sample. They should be planned and reported clearly. A reader should be able to tell whether weights were used, what they were based on, and whether the analysis accounted for them.
Links to broader statistical methods
Cluster sampling can be used before many forms of inferential statistics. A researcher may estimate a mean, compare groups, analyse a proportion, or model relationships between variables. The sampling design does not decide the method on its own, but it affects how uncertainty is estimated.
For example, a study may use correlation analysis to examine two student variables in a school-based cluster sample, or regression analysis to model an outcome from several predictors. In both cases, the analysis should consider that pupils are nested within schools.
Reporting the design in a methods section
A clear report does not need to overwhelm the reader with formulas. It should name the population, cluster frame, cluster selection method, number of clusters selected, method used inside selected clusters, response at each level, and any weights or design corrections used in analysis.
A concise statement might read: “We used two-stage cluster sampling. Schools were selected first from the district school list, with probability proportional to enrolment size. Within each participating school, 30 pupils were selected from the current enrolment roster using a random number generator. Analyses accounted for school clustering and sampling weights.” This tells the reader how the sample was built and how the analysis respected that structure.
Conclusion
Cluster sampling gives researchers a practical way to sample from populations that are naturally organised into groups. Instead of selecting every person, record, household, or observation from one complete individual list, the researcher selects clusters first. Those clusters may be schools, clinics, households, villages, neighbourhoods, sites, or other grouped units.
The method is especially useful when a cluster frame is easier to obtain than an individual frame, or when data collection is more realistic inside selected settings. A one-stage design includes every eligible element inside selected clusters. A two-stage design samples elements within selected clusters. Larger studies may use multistage, PPS, or stratified cluster designs.
At the same time, cluster sampling needs careful handling. Units inside the same cluster often resemble one another, cluster sizes may differ, and response can fail at more than one level. A good cluster sample is a documented route from population to clusters to elements, with analysis that keeps the design in view.
FAQs on Cluster Sampling
What is cluster sampling?
Cluster sampling is a probability sampling method in which researchers randomly select groups, called clusters, and then collect data from all eligible units inside those clusters or from a further sample within them.
What is an example of cluster sampling?
An example is a researcher randomly selecting schools from a district list and then surveying pupils inside the selected schools. The schools are the clusters, and the pupils are the elements measured in the study.
What are the main types of cluster sampling?
The main types are one-stage cluster sampling, two-stage cluster sampling, multistage cluster sampling, probability proportional to size cluster sampling, and stratified cluster sampling. They differ in how clusters and elements are selected.
What is the difference between cluster sampling and stratified sampling?
Cluster sampling selects groups as sampling units, such as schools or clinics, then studies all or some units inside them. Stratified sampling divides the population into categories, such as age groups or regions, and samples within each category to improve planned representation.
When should researchers use cluster sampling?
Researchers should use cluster sampling when the population is naturally grouped, clusters are easier to list than individuals, and data collection is more practical inside selected groups or locations.
What are the limitations of cluster sampling?
Cluster sampling can reduce precision because units inside the same cluster may be similar. It may also need weights, enough selected clusters, careful handling of non-response, and analysis that accounts for the clustered design.



