
Quasi-experimental research is a research design used to study the effect of an intervention, treatment, programme, policy, or exposure when participants cannot be randomly assigned to groups. It resembles experimental research because the researcher is interested in cause and effect, but it does not have the same level of control that a true experiment usually has.
This article explains what quasi-experimental research is, how it differs from experimental and non-experimental research, which designs and methods are often used, how a quasi-experimental study can be performed, and how results should be interpreted in academic research.
What Is Quasi-Experimental Research?
Quasi-experimental research is used when a study aims to examine an effect but does not randomly assign participants, classes, schools, clinics, communities, or other units to conditions. The researcher may still introduce an intervention, compare groups, observe change over time, or analyse a policy that was introduced in one setting but not another. The missing feature is random assignment.
This makes the design useful in many real research settings. Schools may not allow students to be randomly assigned to different teachers. Hospitals may introduce a new patient safety procedure in one ward before another. A government may introduce a policy in one region while neighbouring regions continue as before. In each case, researchers may still want to know whether the change was followed by a meaningful outcome difference.
Quasi-experimental research definition
Quasi-experimental research is a design for estimating the effect of an intervention or exposure when random assignment is not used. It usually compares outcomes across groups, time periods, thresholds, or naturally occurring conditions in order to judge whether the intervention is a plausible explanation for the observed difference.
The word “quasi” means that the design is experiment-like, not that it is informal or weak by definition. A well-designed quasi-experiment can be demanding. The researcher must define the intervention carefully, select a comparison strategy, measure outcomes consistently, and give serious attention to alternative explanations.
Where it fits among research designs
Quasi-experimental research sits between true experimentation and purely observational work. Like experimental research, it focuses on the possible effect of a change. Like many observational designs, it works with groups or exposures that are not fully controlled by the researcher. This position gives it both its usefulness and its difficulty.
For example, a study may compare reading outcomes in two schools after one school adopts a new tutoring programme. The researcher may be able to measure the same outcome in both schools before and after the programme. Still, the students were not randomly assigned to schools. The two schools may differ in prior achievement, staffing, attendance patterns, family background, or other features. A strong quasi-experimental study tries to deal with these differences rather than pretending they are absent.
What quasi-experimental research can show
Quasi-experimental research can provide evidence that an intervention is associated with a change in an outcome. In stronger designs, especially those with careful comparison groups or repeated measurements over time, it can support a cautious causal interpretation. The strength of that interpretation depends on the design and on how well the study handles rival explanations.
The main difficulty is selection. If people, classrooms, clinics, or regions enter the intervention group for reasons connected to the outcome, the estimated effect may mix the intervention with pre-existing differences. This is why quasi-experimental research often relies on pretests, matched comparison groups, interrupted time series, regression adjustment, or designs based on cut-off scores and policy rules.
Objectives of Quasi-Experimental Research
The objectives of quasi-experimental research usually begin with a practical constraint. A researcher wants to study an effect, but random assignment is not available, suitable, or realistic. Instead of abandoning the question, the researcher builds a comparison that is as fair as the setting allows.
This makes quasi-experimental research especially common in education, public health, social policy, clinical services, organisational studies, and community research. These fields often study interventions that operate in real institutions. The research design must follow the shape of the setting while still giving readers a clear route from evidence to conclusion.

Studying effects when random assignment is not possible
The first objective is to estimate the effect of a change when a randomized experiment cannot be used. The reason may be practical. A school may assign students to existing classes before the study begins. A hospital may roll out a new system by ward or by month. A public policy may affect a whole city, not individuals chosen at random.
The reason may also be connected to feasibility, timing, cost, or institutional decision making. Researchers may have to study a programme after it has already started. They may have access to records from before and after a policy change. They may be able to compare exposed and unexposed groups, but not decide who receives the intervention.
Comparing groups, time periods, or thresholds
A second objective is to create a comparison that helps interpret the outcome. Sometimes that comparison is a group that did not receive the intervention. Sometimes it is the same group before and after the intervention. Sometimes it is a cut-off point, such as a test score, income threshold, age boundary, or policy rule that determines who receives support.
The comparison should follow the research question. A study of a new teaching programme may compare students in schools that adopted it with similar students in schools that did not. A study of a new infection-control protocol may examine monthly infection rates before and after implementation. A study of a scholarship may compare students just above and just below an eligibility threshold.
Plain planning question: What comparison would make the intervention group easiest to interpret: another group, an earlier time period, a threshold, or a combination of these?
Strengthening causal interpretation in real settings
A third objective is to make causal reasoning more credible without pretending the study has the same control as a true experiment. A quasi-experimental design does this by reducing the number of plausible alternative explanations. It may use baseline data to show whether groups were similar before the intervention. It may use a control group to show whether a wider trend affected everyone. It may use many time points to separate an intervention effect from normal fluctuation.
This objective connects closely to the research hypothesis. If the hypothesis says that a new programme improves student attendance, the design must do more than show that attendance rose after the programme began. It should ask whether attendance rose more than expected, more than in a comparison group, or more sharply than the previous trend suggested.
Key Aspects of Quasi-Experimental Research
The main aspects of quasi-experimental research are easiest to understand as a chain of design decisions. A researcher begins with a question about an effect, identifies the intervention or exposure, chooses a comparison, measures outcomes, and then analyses whether the observed difference is likely to be explained by the intervention rather than by another factor.
Each part of that chain needs to be visible in the method section. A quasi-experimental study can become difficult to judge when it simply says that one group received a programme and another did not. Readers need to know how the groups were formed, what was measured before the intervention, how outcomes were recorded, and which differences between groups were considered during analysis.
Intervention or exposure
The intervention or exposure is the condition whose effect is being studied. In some projects, the researcher introduces it. A teacher may introduce a new feedback routine, or a clinic may introduce a reminder system. In other projects, the exposure already exists. A policy may have been adopted in one region, or students may have entered a programme because they met an eligibility rule.
The intervention should be described clearly enough that readers can see what changed. A phrase such as “new support programme” is usually too vague. The researcher should explain who received it, when it began, how long it lasted, what activities it included, and whether all participants received the same version.
Comparison structure
The comparison structure is the part of the design that gives the result meaning. A single post-intervention score tells very little by itself. A pretest, a comparison group, a trend line, or a cut-off rule gives the researcher something to compare the outcome against.
Comparison groups are especially useful when they are selected before the outcome is known and when they resemble the intervention group in ways connected to the outcome. If a study compares a new study-skills course in one school with ordinary instruction in another school, readers will want to know whether the schools had similar students, similar prior achievement, similar attendance, and similar assessment conditions.
Baseline data and pretests
Baseline data are measurements taken before the intervention or exposure. They help the researcher judge whether groups were already different. In education, this may be a prior test score. In health research, it may be a symptom measure, diagnosis, risk score, or service-use history. In policy research, it may be a pre-intervention trend.
A pretest does not remove every problem, but it gives the analysis a stronger starting point. If the intervention group was already improving faster before the intervention began, a simple before-after comparison would be misleading. If both groups had similar trends before the policy changed, a later difference is easier to interpret.
Control of alternative explanations
Alternative explanations are other reasons why the outcome may have changed. Students may improve because they were already more motivated. Patients may improve because the clinic changed another procedure at the same time. A community may improve because of a wider economic change rather than the programme being studied.
Quasi-experimental research handles these explanations through design and analysis. Design choices include comparison groups, repeated observations, matching, eligibility thresholds, and clear timing. Analysis choices include regression adjustment, covariates, fixed effects, sensitivity checks, and subgroup comparisons. These tools do not make the study identical to a randomized experiment, but they can make the interpretation more defensible.
Outcome measurement
The outcome is the result the intervention is expected to affect. It may be a test score, attendance rate, hospital infection rate, survey response, service use measure, behaviour count, or administrative record. The outcome should match the research question and should be measured in the same way across groups or time periods.
Measurement can weaken a quasi-experimental study when it changes at the same time as the intervention. If a school adopts a new grading policy while also introducing a teaching programme, later grade differences may reflect the grading change. If a hospital changes its reporting system while introducing a safety intervention, recorded outcomes may shift because of documentation rather than practice.
| Aspect | Question to ask | Why it affects interpretation |
|---|---|---|
| Intervention | What changed, for whom, and when? | The effect cannot be judged if the change is unclear. |
| Comparison | What is the intervention group being compared with? | The comparison shapes the strength of the claim. |
| Baseline | Were groups or trends similar before the intervention? | Pre-existing differences can look like treatment effects. |
| Outcome | Was the outcome measured consistently? | Changed measurement can create false change. |
Quasi-Experimental vs Experimental
Experimental and quasi-experimental research are often compared because both examine possible effects. The difference is not that one studies causes and the other cannot. The sharper distinction is how the groups are formed. In a true experiment, the researcher assigns participants or units to conditions at random. In a quasi-experiment, group membership is not randomized.
This single difference affects the rest of the design. Random assignment helps balance known and unknown differences across groups, at least in expectation. Without it, the researcher must use other ways to judge whether the comparison is fair enough for the claim being made.
Random assignment
Random assignment is the central feature of a true experiment. It means that each participant or unit has a chance-based route into the intervention or control condition. The purpose is not simply to look scientific. It is to make the groups similar before the intervention, so that later differences can more confidently be linked to the intervention.
Quasi-experimental research does not use this process. Students may already be in classes. Patients may choose or be assigned to treatments through ordinary clinical decisions. Communities may receive a policy because of need, geography, timing, or administrative rules. These assignment processes can be related to the outcome, which is why the design has to be handled carefully.
Control and comparison
Experimental research usually gives the researcher more control over who receives the intervention, when it begins, what the control group receives, and how the procedure is carried out. Quasi-experimental research often has less control because the study takes place inside an existing institution or policy environment.
Less control does not mean no structure. A quasi-experimental study may still have a comparison group, a clear treatment date, a pretest, repeated measurements, and a planned analysis. The researcher has to show how these features help separate the intervention from background differences and ordinary change over time.
Internal validity and real settings
True experiments are often strong for internal validity because random assignment helps rule out many rival explanations. Quasi-experiments have to work harder in that area. At the same time, quasi-experimental research often takes place in ordinary schools, clinics, organisations, and communities, which can make the setting closer to the situation where the findings will be used.
The choice between the two is not a simple ranking. When random assignment is possible and appropriate, it is usually a strong option for testing effects. When random assignment is not possible, a carefully planned quasi-experiment may answer a question that would otherwise remain unstudied.
| Feature | Experimental research | Quasi-experimental research |
|---|---|---|
| Intervention | Introduced or controlled by the researcher | Introduced, observed, or shaped by a real setting |
| Assignment | Random assignment | No random assignment |
| Control group | Usually planned by the researcher | May be existing, matched, historical, or absent |
| Main concern | Procedure, compliance, measurement, attrition | Selection, confounding, timing, comparison quality |
Quasi-Experimental vs. Non-Experimental
Quasi-experimental research is also compared with non-experimental research. The boundary can feel less obvious because both may lack random assignment. The difference lies in the role of the intervention or exposure and the kind of claim the study is trying to support.
In non-experimental research, the researcher observes variables as they occur. A correlational research study may examine whether study time is associated with exam score. A descriptive survey may record student attitudes at one point in time. These designs can be useful, but they do not usually introduce or evaluate a specific intervention.
Intervention and comparison
Quasi-experimental research usually has a more intervention-focused structure. There is a programme, policy, treatment, event, threshold, or exposure that creates a contrast. The researcher asks whether the contrast is followed by a difference in the outcome.
Non-experimental research may still compare groups. For example, a study may compare students who work part-time with students who do not. If the researcher is simply observing naturally occurring work status and exam scores, the design is non-experimental. If a school introduces a work-study support programme and the researcher compares outcomes before and after, or with a similar school without the programme, the design moves toward quasi-experimental research.
Interpretation of relationships
Non-experimental studies are often strongest for describing patterns, estimating prevalence, mapping associations, or exploring relationships. Quasi-experimental studies are built to go one step closer to effect estimation. They do this by using timing, comparison, and design rules to make one explanation more plausible than others.
The distinction is useful for writing a methods section. Calling a simple association study quasi-experimental can overstate what the design can show. Calling a policy evaluation non-experimental may understate the fact that the study uses a structured intervention contrast. The label should reflect how the evidence was created, not how strong the conclusion sounds.
Simple distinction: non-experimental research observes variables. Quasi-experimental research uses a planned or naturally occurring intervention contrast to estimate an effect.
Quasi-Experimental Research Designs
Quasi-experimental research designs are different ways of structuring a study when random assignment is not possible. The researcher still studies an intervention, treatment, programme, policy, or change, but the groups are formed through real-world conditions rather than through random allocation.
This is the main reason design choice is so important in quasi-experimental research. Since the researcher cannot rely on random assignment to balance the groups, the design has to create the clearest possible comparison through pretests, comparison groups, repeated measurements, cut-off rules, or carefully matched cases.
Some designs compare an intervention group with a similar group that did not receive the intervention. Others follow the same group before and after a change. Some use many observations over time, while others use an eligibility threshold to compare cases close to a cut-off. Each design gives the researcher a different way to judge whether an observed change is likely to be connected to the intervention.
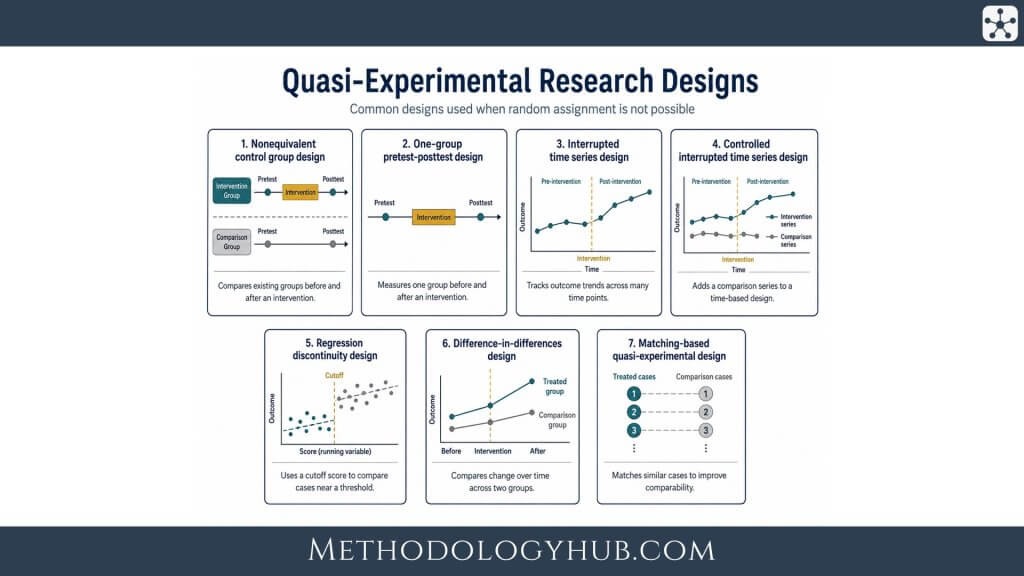
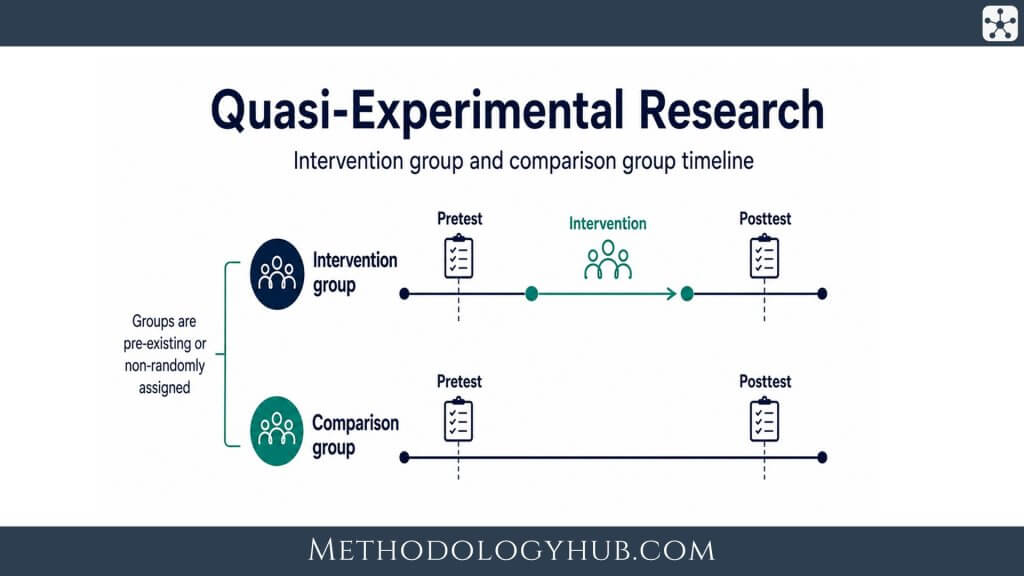
Nonequivalent control group design
A nonequivalent control group design compares an intervention group with a comparison group that was not created through random assignment. This is one of the most common quasi-experimental designs because many real settings already contain groups that can be compared. A school may introduce a new teaching strategy in one class while another class continues with the usual approach. A clinic may adopt a new appointment system while a similar clinic does not.
The groups are called nonequivalent because they may differ before the intervention begins. They may have different backgrounds, levels of prior achievement, health conditions, motivation, access to resources, or other characteristics that can affect the outcome. The design therefore works best when the researcher can measure both groups before and after the intervention.
In a pretest-posttest version, both groups are measured at the start. The intervention group then receives the intervention, while the comparison group does not. Afterward, both groups are measured again. This lets the researcher examine whether the intervention group changed more than the comparison group, while also checking whether the two groups were already different at the beginning.
Simple reading: a nonequivalent control group design is strongest when it includes both a comparison group and a pretest, because the researcher can examine starting differences as well as later change.
One-group pretest-posttest design
A one-group pretest-posttest design measures one group before and after an intervention. For example, students may complete a writing assessment before a workshop and again after the workshop. The researcher then compares the two scores to see whether change occurred.
This design is easy to understand and often practical, especially in small-scale evaluations, classroom projects, pilot studies, or local programme reviews. It can show whether the outcome changed after the intervention was introduced. However, it does not include a comparison group, so the interpretation needs caution.
The main difficulty is that change may have other explanations. Students may improve because they became more familiar with the test. Patients may improve because symptoms naturally changed over time. A community outcome may shift because of an outside event that happened during the study period. Without a comparison group, it is difficult to separate the intervention from these alternative explanations.
For this reason, the one-group pretest-posttest design is usually weaker than designs with a comparison group. It can still be useful when the goal is early evidence, internal monitoring, or local improvement, but it should not be presented as if it gives the same causal support as a stronger quasi-experimental design.
Interrupted time series design
An interrupted time series design uses repeated measurements before and after an intervention. Instead of relying on one pretest and one posttest, it studies a pattern over time. A hospital might track monthly infection rates before and after a new hygiene protocol. A school district might follow attendance rates before and after a new attendance policy.
The strength of this design is that it shows the trend before the intervention, the point where the intervention began, and the trend after the intervention. The researcher can ask whether the level changed, whether the direction of the trend changed, or whether the rate of change became stronger or weaker after the intervention.
This design is especially useful when outcome data are already collected routinely. Administrative records, monthly reports, clinic data, school attendance logs, crime statistics, service use records, and test score trends can all support an interrupted time series if the measurements are consistent across time.
The design becomes more convincing when there are enough observations before and after the intervention. A single measurement before and after the intervention does not show a time series. The researcher needs enough data points to see whether the post-intervention pattern differs from the earlier pattern.
Controlled interrupted time series design
A controlled interrupted time series design adds a comparison series to the interrupted time series. The researcher observes trends over time in an intervention setting and in a similar setting that did not receive the intervention.
This design helps when wider changes could affect the outcome. For example, if a city introduces a traffic safety programme and road accidents decrease afterward, the decrease may be connected to the programme. But it may also reflect seasonal driving patterns, fuel prices, weather, national regulations, or broader public campaigns. A comparison city measured over the same period gives the researcher a better basis for judging whether the change was specific to the intervention setting.
The comparison series does not have to be perfect, but it should be chosen carefully. It should be similar enough to show what might have happened without the intervention. If the comparison setting is very different from the intervention setting, the design may still be difficult to interpret.
Regression discontinuity design
A regression discontinuity design is used when assignment to an intervention is based on a clear cut-off score or threshold. Students below a reading benchmark may receive extra tutoring. Patients above a risk score may receive additional support. Households below an income threshold may qualify for a programme.
The design focuses on cases close to the cut-off. The logic is that people just below and just above the threshold may be very similar, except that one side receives the intervention and the other side does not. If the outcome changes sharply at the cut-off, and the threshold was applied consistently, the design can support a stronger causal interpretation than many other non-randomized designs.
The cut-off must be real and clearly defined. If researchers move the threshold after seeing the data, or if participants can easily manipulate their position around the threshold, the design becomes weaker. A regression discontinuity design depends on the credibility of the assignment rule.
Difference-in-differences design
A difference-in-differences design compares change over time in an intervention group with change over time in a comparison group. The basic question is whether the intervention group changed more than the comparison group after the intervention began.
Suppose one region introduces a school meal subsidy while a similar region does not. The researcher measures an outcome, such as attendance, before and after the policy in both regions. The analysis then compares the change in the intervention region with the change in the comparison region.
The design is useful in policy evaluation because many policies are introduced in one location, institution, or population before they appear elsewhere. However, the interpretation depends on whether the comparison group gives a reasonable picture of what would have happened to the intervention group without the intervention. If the groups were already moving in different directions before the intervention, the design becomes less convincing.
Matching-based quasi-experimental design
A matching-based quasi-experimental design tries to create a fairer comparison by pairing or grouping intervention cases with similar non-intervention cases. The researcher may match students by prior achievement, age, grade level, attendance, or other baseline characteristics. In health research, patients may be matched by diagnosis, risk level, age, or previous treatment history.
The purpose is to reduce visible differences between the intervention and comparison groups before the outcome is analysed. If the groups are more similar at baseline, the final comparison becomes easier to interpret.
Matching can improve a quasi-experimental study, but it cannot solve every problem. It only works with variables that were measured and included in the matching process. If important differences were not measured, they can still affect the result. The design is strongest when the researcher has good baseline data and a clear reason for choosing the matching variables.
Choosing a quasi-experimental design
The best design depends on the intervention, setting, available data, and comparison that can be defended. A school programme with similar classes may fit a nonequivalent control group design. A policy introduced at a known date may fit an interrupted time series or difference-in-differences design. A programme assigned by eligibility score may fit a regression discontinuity design.
| Design | Best fit | Main caution |
|---|---|---|
| Nonequivalent control group | Existing groups can be compared before and after an intervention. | Groups may differ before the intervention begins. |
| One-group pretest-posttest | Only one group is available for before-and-after measurement. | Change may have explanations other than the intervention. |
| Interrupted time series | Repeated outcome data are available before and after the intervention. | Other events at the same time may affect the trend. |
| Regression discontinuity | An intervention is assigned by a clear cut-off score or threshold. | The cut-off must be applied consistently and not manipulated. |
| Difference-in-differences | An intervention affects one group, location, or period but not another comparable one. | The comparison group should reflect the likely trend without the intervention. |
| Matching-based design | Intervention and comparison cases can be matched using good baseline data. | Matching cannot adjust for important variables that were not measured. |
The researcher should not choose the design only because it is familiar. The design should fit the way the intervention actually occurred. It should also make the comparison transparent enough for readers to understand what the study can and cannot claim.
How to Perform Quasi-Experimental Research
Performing quasi-experimental research means turning a practical situation into a design that readers can follow and evaluate. The work begins before the analysis. A researcher needs to know what effect is being studied, which units receive the intervention, which comparison is available, and which variables may confuse the interpretation.
The steps below give a general route. Some studies will use more advanced statistical modelling, and some will remain small and local. In both cases, the design should be explained clearly enough that another reader can see how the conclusion was reached.
Step 1: Define the research question
Begin with a focused question. “Does the programme work?” is usually too broad. A stronger question names the intervention, the outcome, the group, and the time period. For example: “Did the new peer tutoring programme improve mathematics scores among Grade 8 students over one semester compared with similar students who did not receive tutoring?”
The research question should also match the available design. If the study has no comparison group and only one pretest and one posttest, the question should not promise a strong causal estimate. If the study has several years of monthly data and a suitable comparison site, the question can be more ambitious.
Step 2: Identify the intervention and units of analysis
The researcher should state what the intervention is and what unit is being analysed. The unit may be a person, classroom, school, clinic, ward, neighbourhood, organisation, document, or time period. Confusion can appear when the intervention is assigned at one level but the analysis is conducted at another.
For example, a policy may be introduced at the school level, while outcomes are measured for individual students. The analysis then needs to recognise that students are grouped within schools. Treating every student as fully independent can make the results look more precise than they are.
Step 3: Choose the comparison strategy
The comparison strategy is the centre of the design. The researcher may use a comparison group, a historical comparison, repeated observations, a cut-off, matched cases, or a combination of these. The choice should be made before looking for the most favourable result.
A useful comparison is not always perfect. It should be plausible and transparent. If the comparison group differs from the intervention group, the researcher should report those differences and, where possible, account for them in the analysis.
Step 4: Measure baseline characteristics and outcomes
Baseline characteristics help readers judge whether the intervention and comparison groups differ in ways that could affect the outcome. These may include prior performance, age, diagnosis, attendance, location, socioeconomic measures, or earlier outcome values. The choice depends on the study.
The outcome should be measured in the same way for all groups and time points. If records, tests, surveys, or observation procedures change during the study, the researcher should explain how this affects interpretation.
Step 5: Plan the analysis before interpreting the results
The analysis plan should follow the design. A nonequivalent group design may use regression adjustment or analysis of covariance. A difference-in-differences design compares changes in two groups. An interrupted time series may use segmented regression. A regression discontinuity design models the relationship between the assignment variable and the outcome around the cut-off.
This is where statistical methods and statistical analysis become part of the design rather than a final add-on. The test or model should answer the research question and respect the way the data were produced.
Step 6: Interpret results with the design limits in view
The interpretation should return to the design. If the intervention group improved more than the comparison group, the researcher can discuss whether the pattern is consistent with the intended effect. At the same time, the report should consider remaining differences between groups, missing data, changes in measurement, and events that occurred during the study period.
A good conclusion does not need to weaken itself with vague language. It simply states what the evidence supports. For example, a study might conclude that the intervention was associated with a larger improvement than the comparison condition, while noting that unmeasured differences between groups cannot be ruled out.
Examples of Quasi-Experimental Research
Examples of quasi-experimental research appear in many academic fields because many interventions cannot be randomized easily. The examples below are simplified, but they show the kind of design logic researchers use when studying effects in ordinary settings.
Education example
A school introduces a new reading programme for Grade 4 students. Another school in the same district continues with the usual curriculum. Both schools administer the same reading assessment at the start and end of the year. The researcher compares the change in reading scores across the two schools.
This is quasi-experimental because the students were not randomly assigned to schools or programmes. The design becomes stronger if the two schools had similar prior achievement, used the same assessment, had similar testing conditions, and provided enough baseline information to judge group differences.
Public health example
A city introduces a campaign to increase vaccination appointments. Researchers examine weekly appointment rates for one year before and one year after the campaign. They also compare the pattern with a nearby city that did not introduce the campaign during the same period.
This could be a controlled interrupted time series. The repeated measurements show the trend before and after the campaign, while the comparison city helps separate the campaign from wider seasonal changes, media coverage, or national policy shifts.
Clinical service example
A clinic introduces a text-message reminder system to reduce missed appointments. Patients are not randomly assigned to receive reminders. Instead, the system begins on a particular date for all patients in the clinic. Researchers compare missed appointment rates before and after the system begins, and they adjust for patient age, appointment type, and previous attendance history.
This design can show whether missed appointments declined after the reminder system was introduced. It is stronger if there are several measurements before and after implementation, and stronger again if a similar clinic without the reminder system is available for comparison.
Policy example
A region changes the eligibility threshold for a student grant. Students just below the income threshold qualify for support, while students just above it do not. Researchers compare educational outcomes for students near the cut-off.
This example fits regression discontinuity when the threshold is applied consistently. Students close to the cut-off are likely to be more comparable than students far apart on the income scale. The design therefore uses the rule itself to create a structured comparison.
Methodological Approaches in Quasi-Experimental Research
Methodological approaches in quasi-experimental research focus on improving comparison and making assumptions visible. Since random assignment is absent, the researcher needs to explain why the comparison is suitable and what conditions must hold for the interpretation to be convincing.
These approaches are technical decisions, and they also shape how the study is written. A reader should be able to see which alternative explanations were considered, which were addressed by design, which were addressed by analysis, and which remain as limits.
Baseline adjustment
Baseline adjustment uses pre-intervention information in the analysis. If one group begins with higher scores, better health, or lower risk, the analysis can account for that difference. In quantitative work, this is often done through regression models or analysis of covariance.
Adjustment is useful, but it depends on measurement. It can only account for variables that were recorded well enough to be used. If the study omits an important pre-existing difference, the adjusted result may still be biased.
Repeated measures and trend analysis
Repeated measures give the researcher more information about ordinary variation. A single before-after comparison can be unstable because one measurement before the intervention may be unusually high or low. Several measurements before and after the intervention show whether the change is unusual relative to the earlier pattern.
Trend analysis is especially useful for service, policy, and administrative data. It can show whether the intervention is associated with an immediate level change, a gradual slope change, or both. The interpretation should consider other events that occurred around the same time.
Matching and weighting
Matching and weighting aim to make the intervention and comparison groups more similar on measured characteristics. These approaches are often used when the researcher has a large dataset with information about participants before the intervention.
The logic is simple, even when the statistics are more advanced. A student who received an intervention is compared with one or more students who looked similar before the intervention. If the matched groups differ afterward, the result is less likely to be explained by the measured baseline variables. The phrase “measured variables” is important because unmeasured differences can still remain.
Sensitivity analysis
Sensitivity analysis asks whether the conclusion changes under different reasonable choices. The researcher may try alternative comparison groups, different model specifications, different time windows, or different ways of handling missing data. If the result appears only under one narrow set of choices, the conclusion should be cautious.
In quasi-experimental research, sensitivity analysis is especially useful because many assumptions cannot be proven directly. The goal is not to make uncertainty disappear. It is to show readers how stable the finding is when the analysis is examined from more than one angle.
Conclusion
Quasi-experimental research gives researchers a way to study effects when random assignment is not available. It is used when schools, clinics, organisations, communities, or policies create real contrasts that can be studied systematically. The design is especially useful when the question concerns a programme, intervention, treatment, exposure, or policy that cannot be tested through a true experiment.
The strength of quasi-experimental research depends on comparison. A simple before-after change may be useful for early evidence, but it leaves many explanations open. A study with a suitable comparison group, baseline data, repeated measurements, or a clear eligibility threshold can support a stronger interpretation. The more clearly the study deals with selection, timing, measurement, and alternative explanations, the easier it is for readers to judge the result.
Quasi-experimental research should therefore be written with design logic at the centre. The researcher should explain who received the intervention, how the comparison was formed, what was measured before and after, which variables may have affected group membership, and which analytic approach was used. When these parts are aligned, quasi-experimental research can make a useful contribution to evidence in settings where a randomized experiment is not possible.
FAQs on Quasi-Experimental Research
What is quasi-experimental research?
Quasi-experimental research is a study design used to estimate the effect of an intervention, treatment, policy, programme, or exposure without random assignment. It compares groups, time periods, thresholds, or matched cases to judge whether the intervention is a plausible explanation for the outcome.
What is the main feature of quasi-experimental research?
The main feature of quasi-experimental research is that it studies an intervention or exposure without random assignment. Participants or units are placed in conditions through existing groups, policy rules, eligibility thresholds, institutional decisions, or natural circumstances.
How is quasi-experimental research different from experimental research?
Experimental research uses random assignment to place participants or units into conditions. Quasi-experimental research does not use random assignment. Because of this, quasi-experimental studies need careful comparison strategies to handle pre-existing group differences.
How is quasi-experimental research different from non-experimental research?
Non-experimental research observes variables without structuring an intervention contrast. Quasi-experimental research studies the possible effect of an intervention, exposure, policy, event, or treatment, but does so without random assignment.
What are examples of quasi-experimental research designs?
Examples of quasi-experimental research designs include nonequivalent control group designs, one-group pretest-posttest designs, interrupted time series designs, controlled interrupted time series designs, regression discontinuity designs, difference-in-differences designs, and matched comparison designs.



